6 Plotting with ggplot2
Graphics are very important for data analysis. On the one hand, we can use it for exploratory data analysis to discover any hidden relationships or simply to get an overview. On the other hand, we need graphics to present results and communicate them to others.
There are several ways to create graphics in R. With the original graphics system (R Base Graphics) we can quickly create simple plots. It is very powerful and flexible, but the problem is that the syntax looks a bit archaic, and it is difficult for beginners to customize graphics.
In contrast, ggplot2 is based on an intuitive syntax, the so-called Grammar
of graphics. Once you get
used to it, you can create very complex graphics with an elegant and consistent
“grammar”. ggplot2 is designed to work with tidy data, i.e. we need data in
long format. Plots are always created according to the same principle:
Start by preparing a dataset so that it is in the right format.
Create a plot object using the function
ggplot().Define so-called “aesthetic mappings”, i.e. determine which variables should be displayed on the X and Y axes and which variables are used to group the data. The function we use for this is called
aes().Add one or more “layers” to the plot. These layers define how something should be displayed, e.g. as a line or as a histogram. These functions begin with the prefix
geom_, e.g.geom_line().Add further specifications, such as the colour scheme that should be used, and possibly facetting by levels of a grouping variable.
To use ggplot2 we need an additional operator: +. You already know this as a
mathematical operator, but in this context, the use of + means that we combine
individual elements of a plot object.
Let us look at a practical example: We want to compare female and male adolescents with regard to their experienced level of psychological stress. Rather than comparing only the sample means we want to plot the distributions themselves.
Now we load the example data set again, this time we use a version with variable names and value labels already in English (and without all the single items). We also convert all grouping variables in the data set to factors:
library(tidyverse)
library(haven)
adolescents <- read_sav("data/exampledata_english.sav") %>%
mutate_at(vars(ID, region, gender, starts_with("edu")), as_factor) and create a data set containing only the variables ID, gender and stress_psych.
# we use dplyr:: before select() to make sure that the select() function from
# dplyr is not masked by select() functions from other packages
stress <- adolescents %>%
dplyr::select(ID, gender, stress_psych) %>%
drop_na()
stress## # A tibble: 284 × 3
## ID gender stress_psych
## <fct> <fct> <dbl>
## 1 1 female 1.67
## 2 2 male 3.5
## 3 10 female 3.67
## 4 11 female 1.5
## 5 12 female 2.5
## 6 14 male 1
## 7 15 male 2.5
## 8 16 female 3.5
## 9 17 male 1.67
## 10 18 male 2.5
## # … with 274 more rowsIn this data set we have a numeric variable, stress_psych and a grouping
variable gender. Our question was whether the variable stress_psych is
related to the grouping variable gender. We could graphically illustrate this
relationship in various ways: with dots, with a box plot or with a violin plot.
These three methods are geoms in the language of ggplot2 and can be used as
follows: geom_point (), geom_boxplot() or geom_violin(). In addition,
there is a function geom_jitter() that spatially jitters the data points (as
an alternative to displaying data points with the same value on top of each
other).
We can load the ggplot2 package individually or as part of the tidyverse:
library(ggplot2)
# or
library(tidyverse)6.1 Step 1: Creating a plot object
We start with a data set and create a plot object with the function ggplot().
This function has a data frame as the first argument. This means that we can use
the pipe operator:
We have two options. We prefer the pipe notation here, but it is also possible
to specify the data frame as an argument within the function. Furthermore, we
assign the object to a variable and call it p.
# 1st option
p <- ggplot(data = stress)
# 2nd option
p <- stress %>%
ggplot()6.2 Step 2: Aesthetic mappings
With the second argument mapping we now define the “aesthetic mappings”. These
determine how the variables are used to represent the data and are defined using
the aes() function. We want to represent the factor gender on the
X-axis and stress_psych should be displayed on the Y-axis. In addition,
aes() can have additional arguments: fill, color, shape,linetype,
group. These are used to assign different colors, shapes, lines, etc. to the
levels of (optional) grouping variables.
In this introductory example, gender is both the variable on the X-axis as well as additionally plays the role of a grouping variable because want the two levels of gender to be plotted in (generally to have) different colors and to be also filled in with different colors (color is an attribute of lines or points, fill is an attribute of areas). We will later see examples where the grouping variable is an additional factor variable that is not used on either the X- or the Y-axis.
If we define the “aesthetic mappings” within the function ggplot(), they apply to all “layers”, i.e. for all elements of the plot. We could also define these mappings separately for each “layer” (see below for examples).
p <- stress %>%
ggplot(mapping = aes(x = gender,
y = stress_psych,
color = gender,
fill = gender))p is now an “empty” plot object. We can look at it, but nothing is displayed yet, as it does not yet contain “layers”. A ggplot2 object is displayed by having the object sent to the console, either with or without print ().
p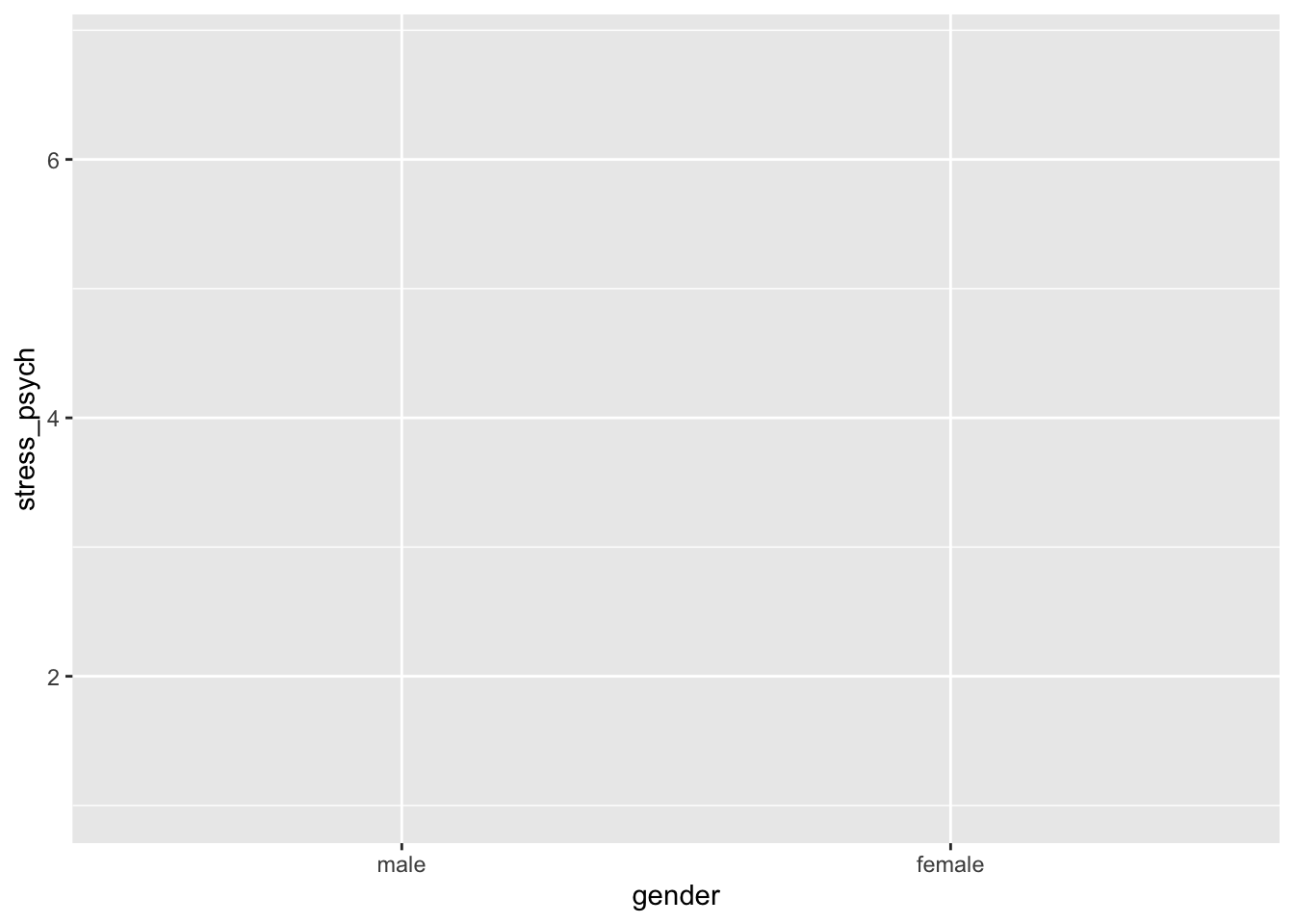
# or print(p)We can see that ggplot2 has already labeled the axes for us using the variable names.
6.3 Step 3: Add geoms
Using the geom_ functions we can now add “layers” to the plot object p. The syntax works like this: We “add” (+) a geom to the plot object p: p + geom_.
6.3.1 Scatter plot
We first try to represent the observations as points:
# the geom_point() function has a size argument
p + geom_point(size = 3)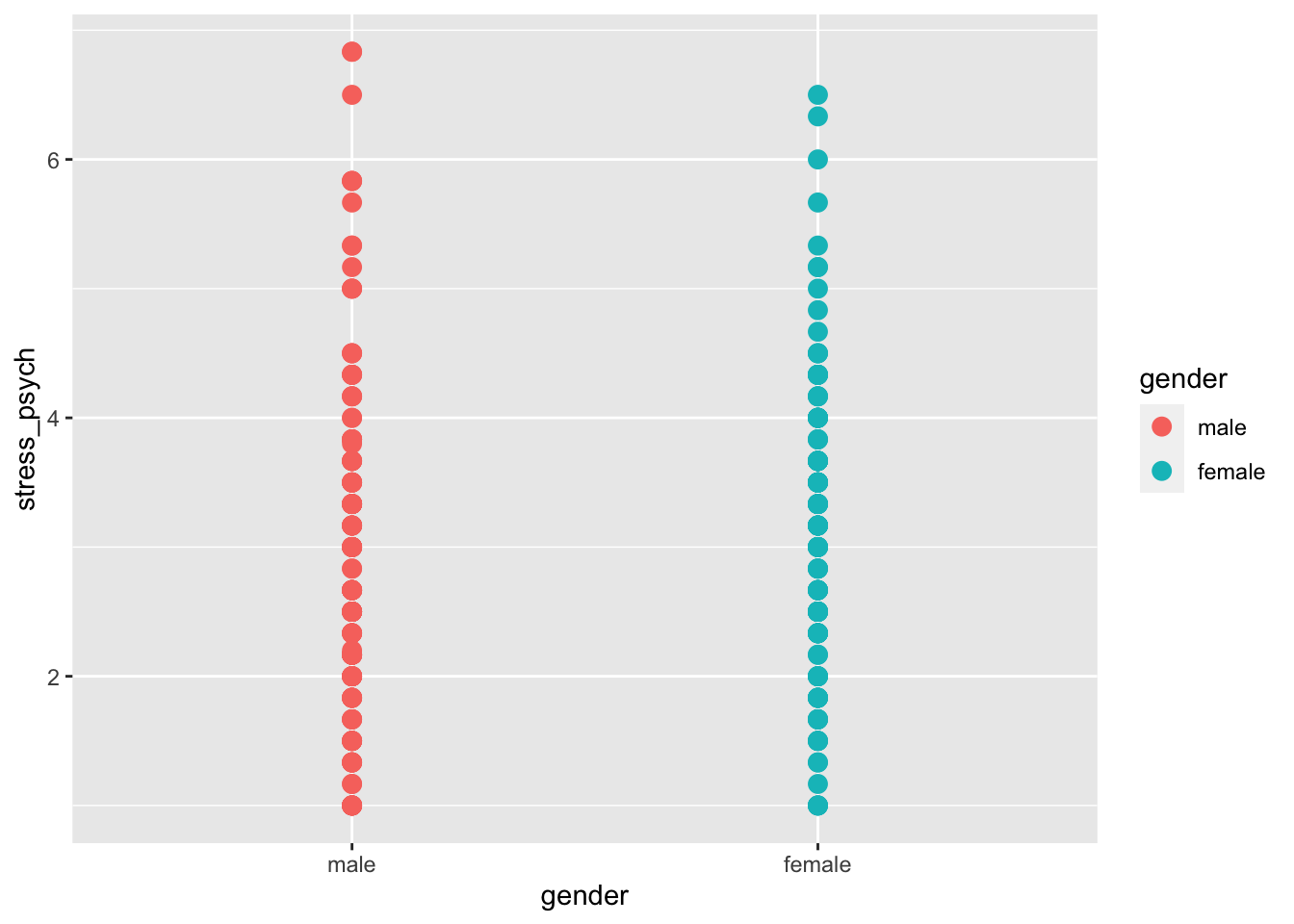
The points are now displayed in different colors, but within a gender points may be plotted on top of each other if they have the same value (overplotting). In this case, there is the function geom_jitter (), which draws points with a jittering side by side:
p + geom_jitter()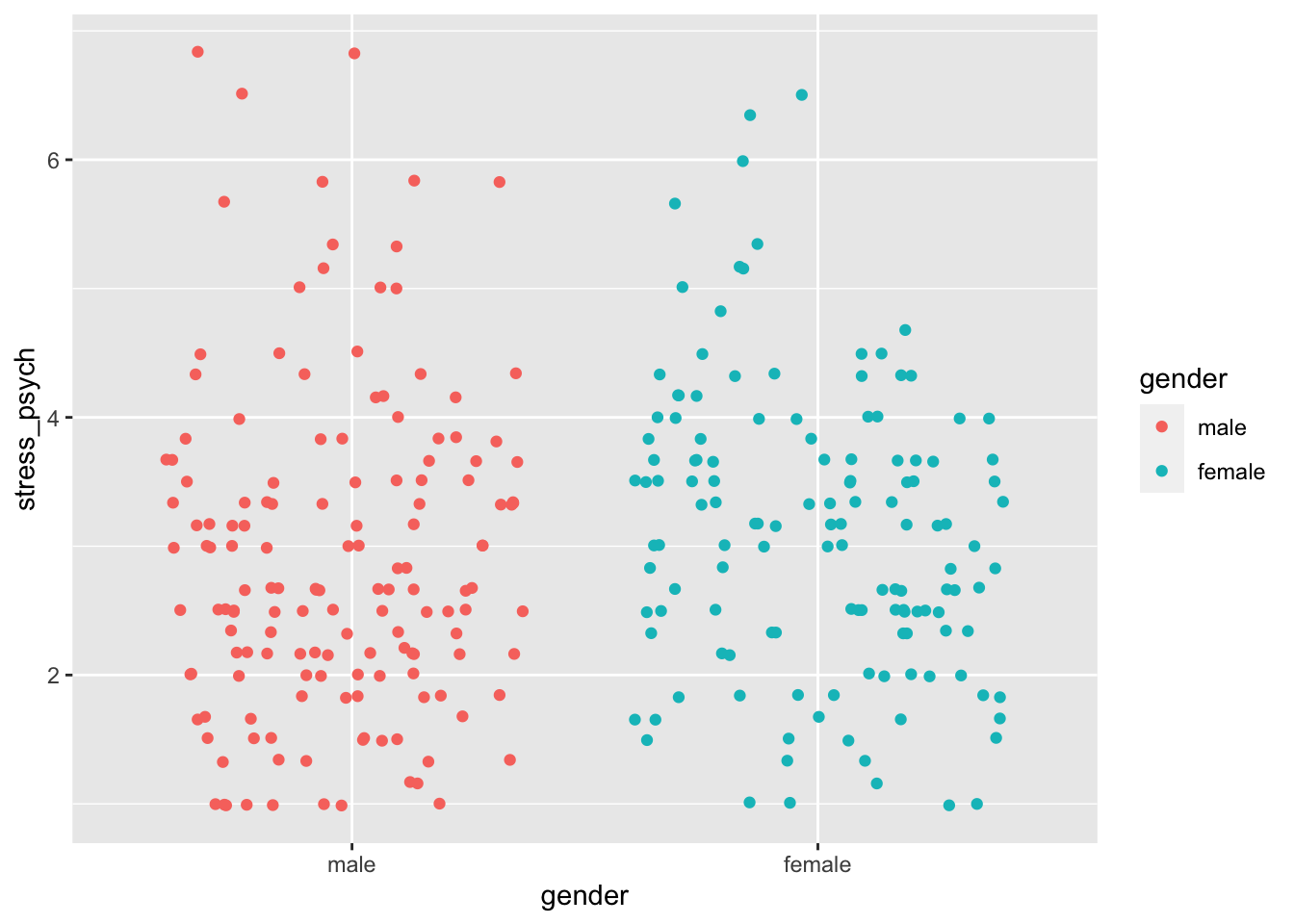
geom_jitter () has an argument width, with which we can define how widely the points are being jittered.
p + geom_jitter(width = 0.2)
geom_jitter() has further arguments: size determines the diameter of the points, alpha determines their transparency.
p + geom_jitter(width = 0.2, size = 4, alpha = 0.6)
6.3.2 Visualizing a distribution
Another possibility is to represent the central tendency and dispersion of the data with a box plot or a violin plot.
p + geom_boxplot()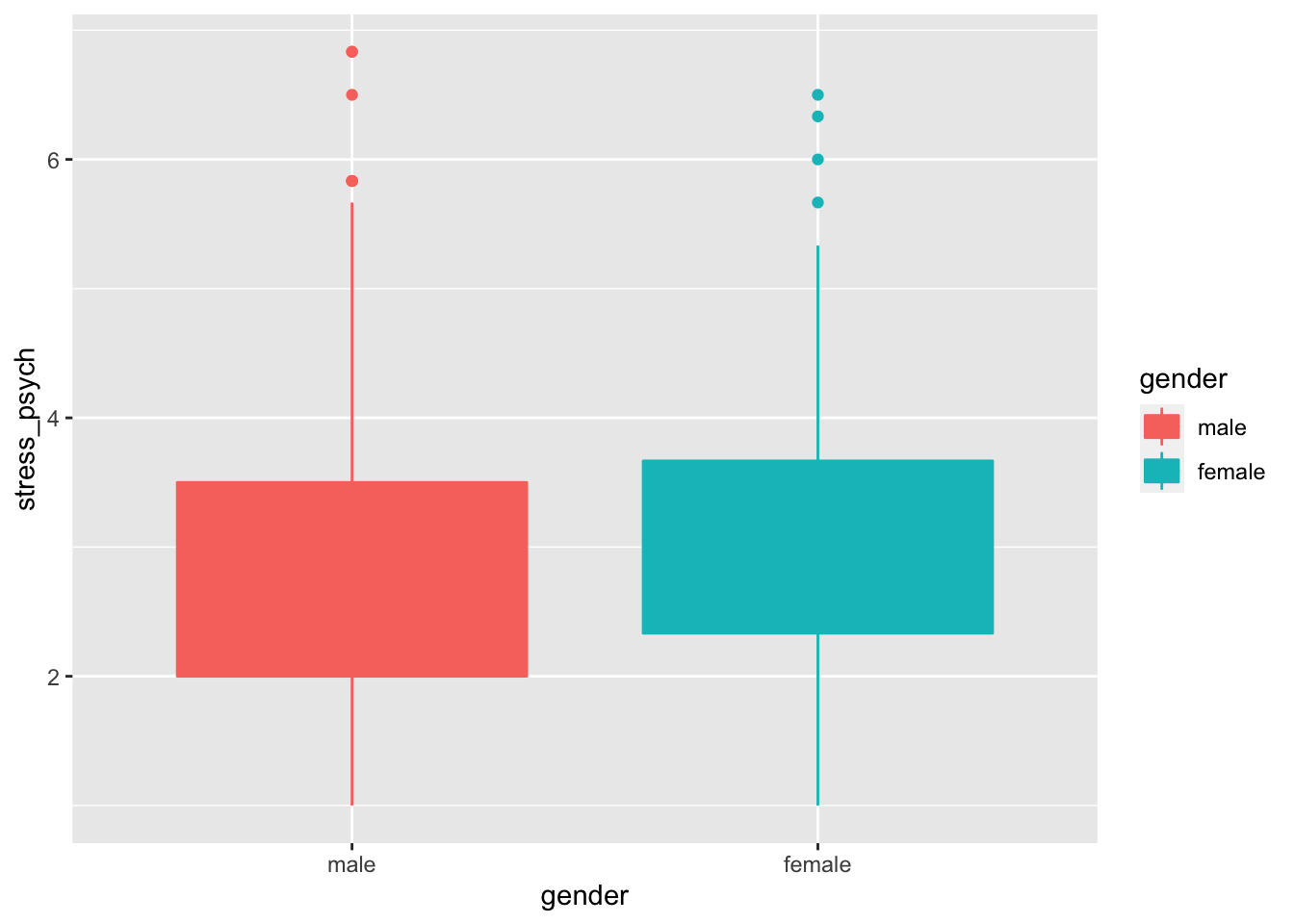
In a box plot, the median is displayed, the rectangle represents the middle 50%, and the whiskers show 1.5 * the interquartile range. Outliers are represented by dots. To actually see the median in the diagram, it is better to omit the fill attribute:
p <- stress %>%
ggplot(mapping = aes(x = gender,
y = stress_psych,
color = gender))
p + geom_boxplot()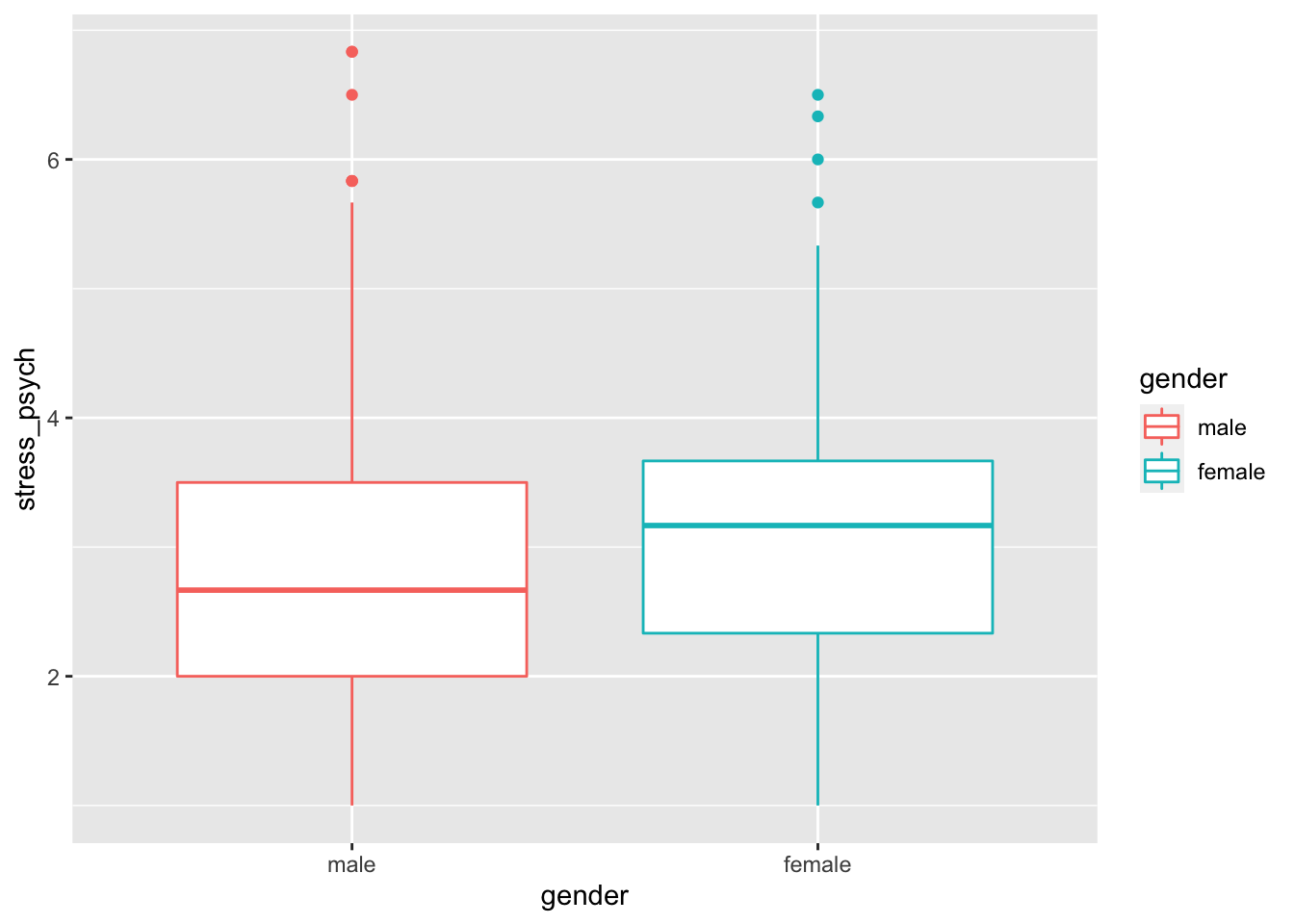
A violin plot is similar to a box plot, but instead of the quantiles it shows a kernel density estimate. A violin plot looks best when we use the fill attribute.
p <- stress %>%
ggplot(mapping = aes(x = gender,
y = stress_psych,
fill = gender))
p + geom_violin()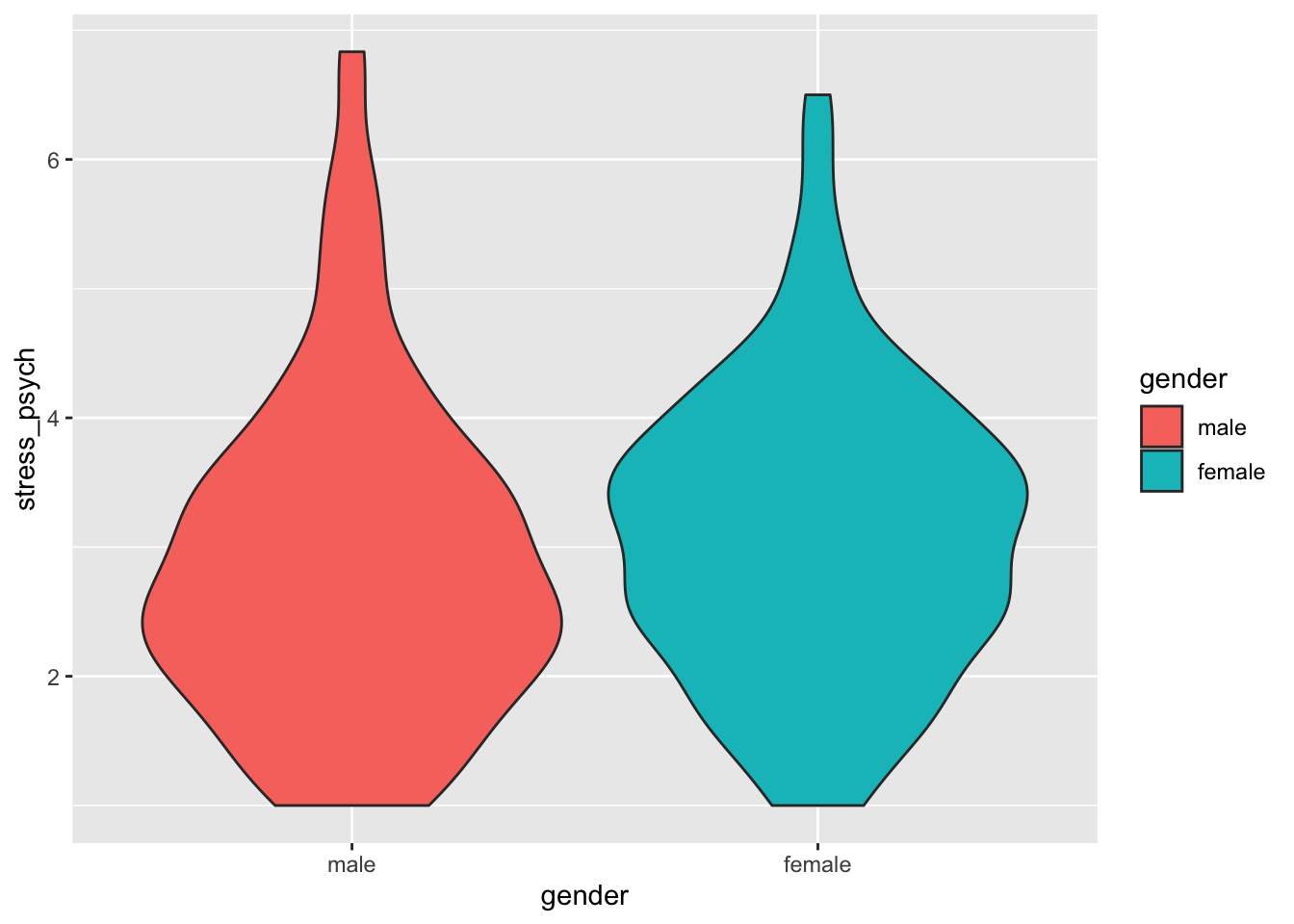
If we find that a mapping should not apply to all “layers” then we can define it individually for each “layer” rather than in the ggplot() function:
p <- stress %>%
ggplot(mapping = aes(x = gender,
y = stress_psych))p + geom_boxplot(mapping = aes(color = gender))# or simply
p + geom_boxplot(aes(color = gender))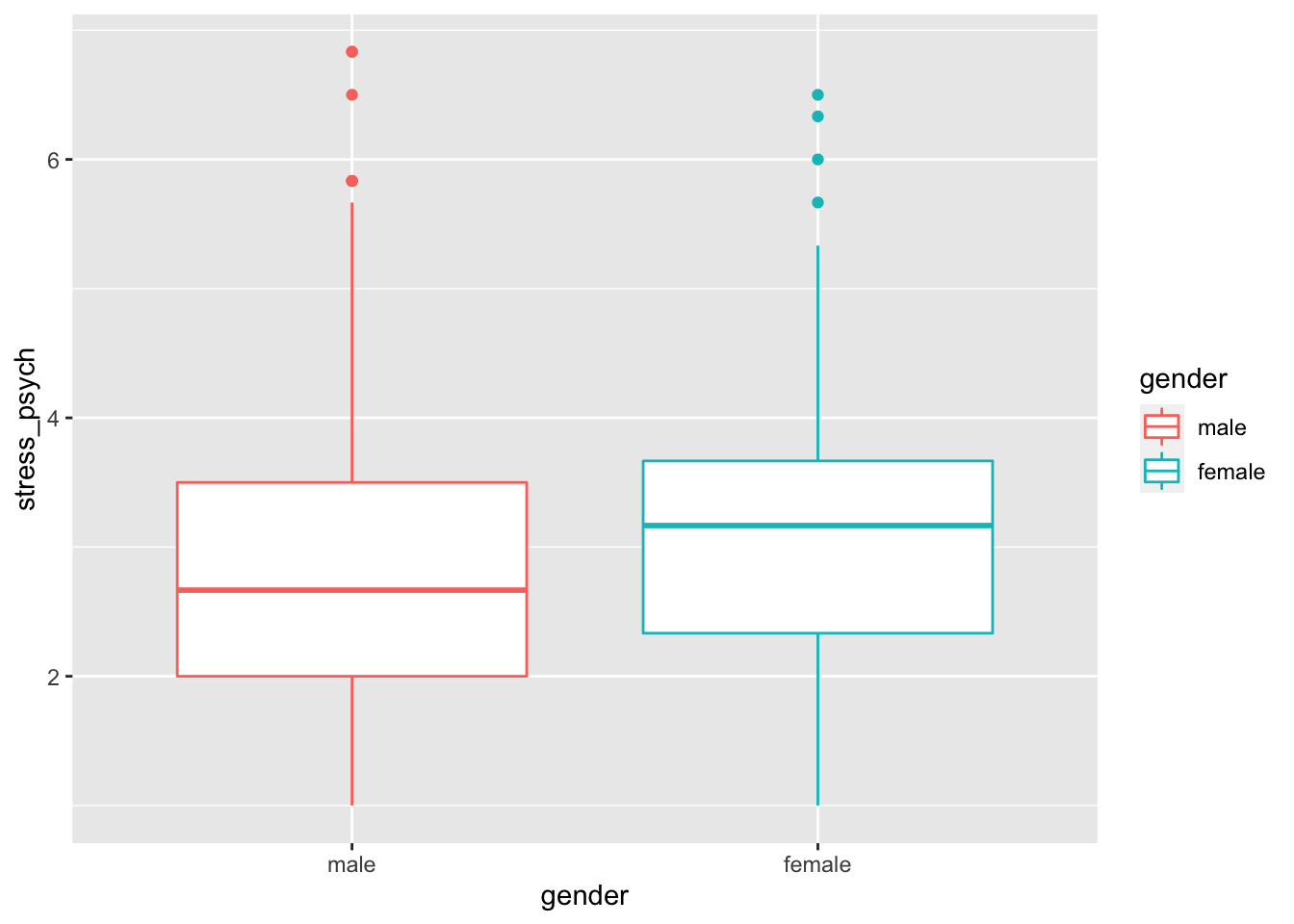
p + geom_violin(aes(fill = gender))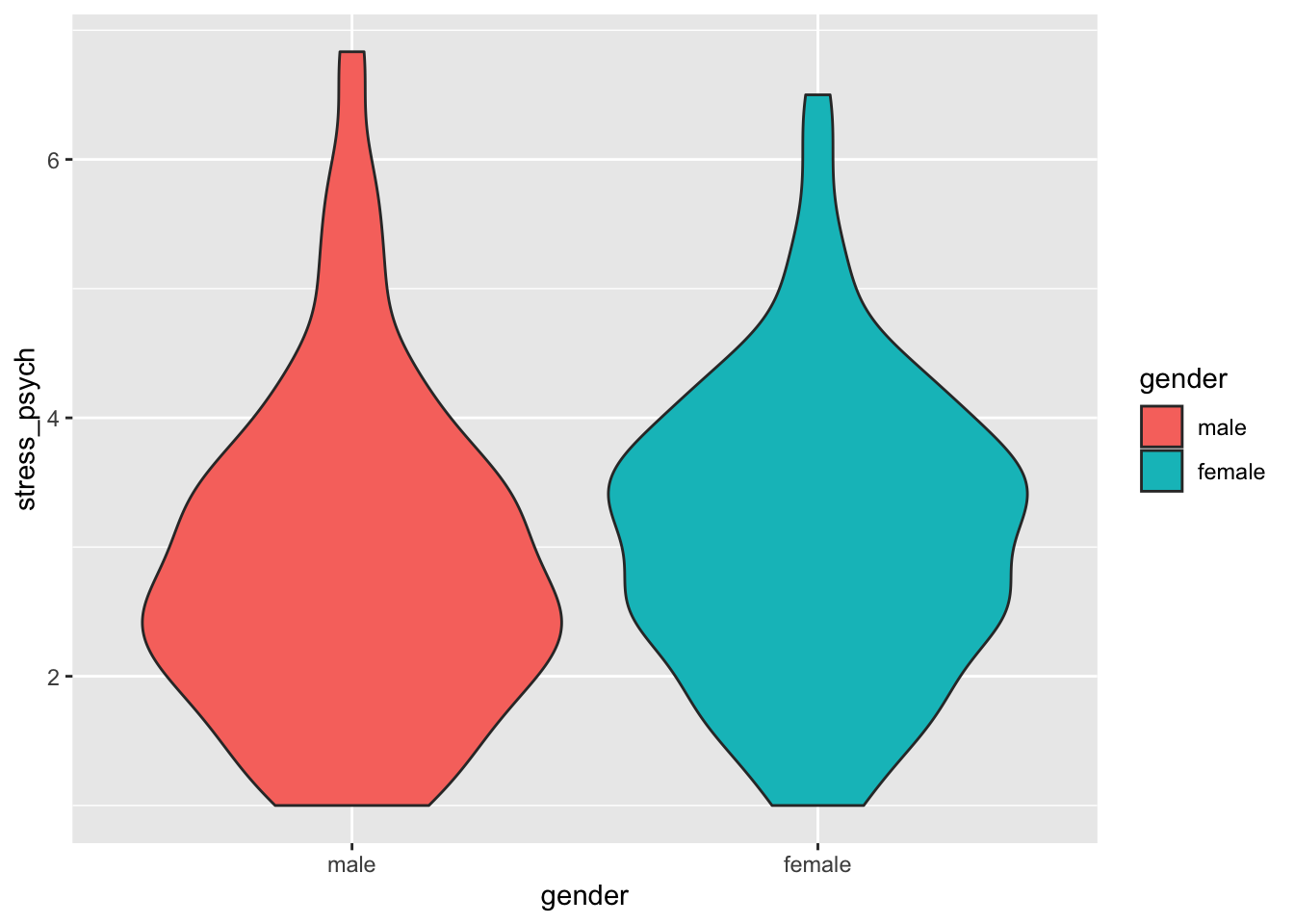
6.3.3 Combining multiple layers
We can also use multiple layers. We just need to combine several geom_ functions with a +:
p +
geom_violin(aes(fill = gender)) +
geom_jitter(width = 0.2, alpha = 0.6)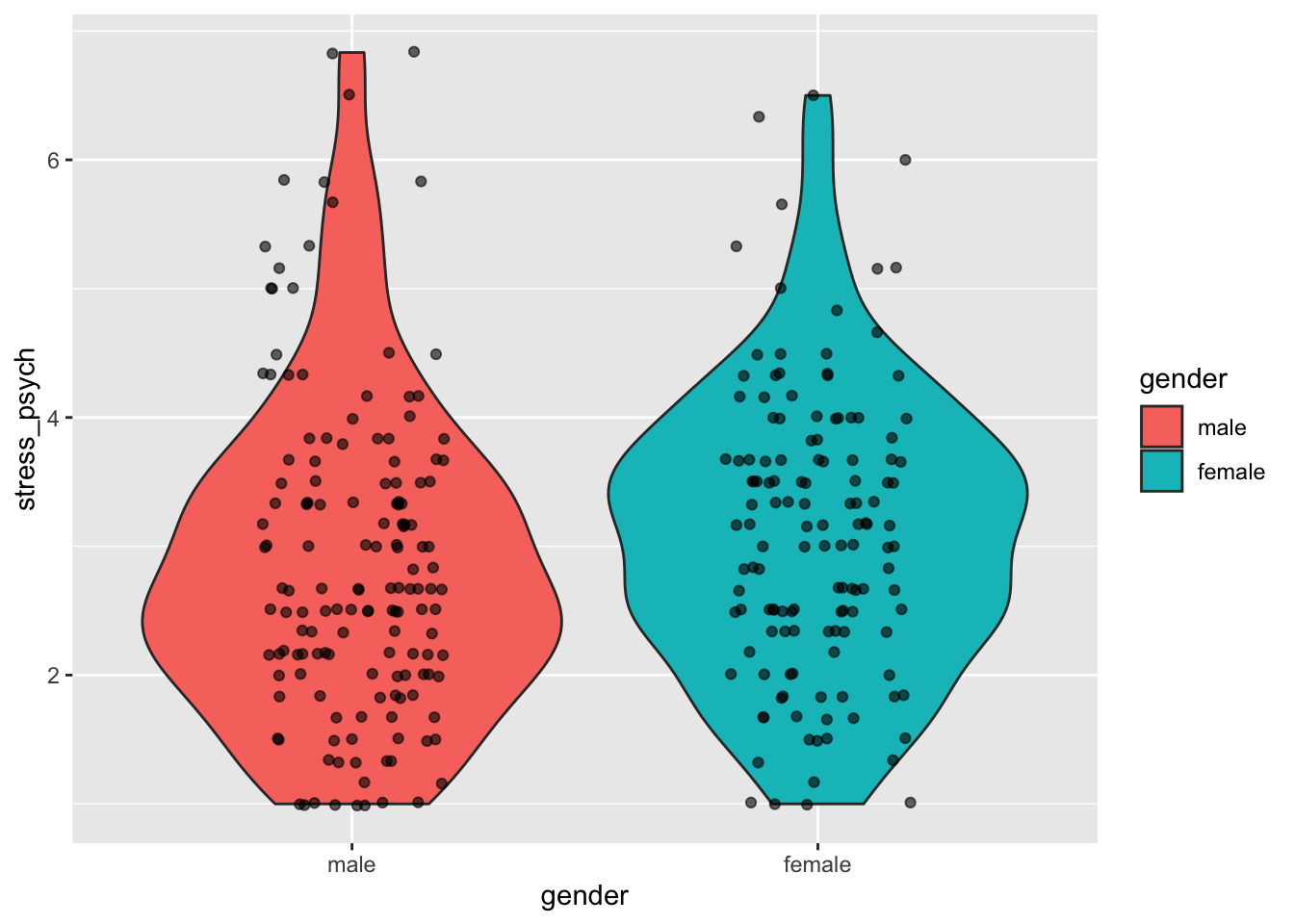
6.4 Geoms for different data types
Let’s summarize: so far we have learned how to put together a plot in several
steps. We start with a data frame and define a ggplot2 object using the
ggplot() function. With the aes() function, we assign variables of a
data frame to the X or Y axis and define further “aesthetic mappings”, e.g. a
color coding based on a grouping variable. Then we add graphic elements with
geom_ * functions as “layers” to the plot object.
Now let’s look at a selection of geoms for different combinations of variables. We can either display one variable on the X axis or two variables on the X and Y axes, and these variables can be either continuous or categorical.
We will consider here only a small selection of the possible ggplot2 functions. The package is very extensive and has a very good website where everything is documented:
ggplot2 Dokumentation
After working through this chapter, you will be able to find graphical visualization solutions yourself. Data visualization can be a very creative process and is fun! Further examples of specific data analysis methods can be found in the following chapters.
6.4.1 One variable
Even if we want to display only one variable (on the X-axis), we still have to represent some values on the Y-axis. This will often be a descriptive summary such as the frequencies of a categorical variable.
Categorical variable
When we plot a categorical variable, we often use a bar chart or bar
graph. This plot represents the frequencies of the different categories based
on a rectangle (rectangular bar). The function that is used for this is called
geom_bar().
As an example we want to plot the frequencies of the four levels of education of the father from the adolescents data set:
p <- adolescents %>%
dplyr::select(edu_father) %>%
drop_na() %>%
ggplot(aes(x = edu_father))
p + geom_bar(fill = 'lightblue', color = 'black')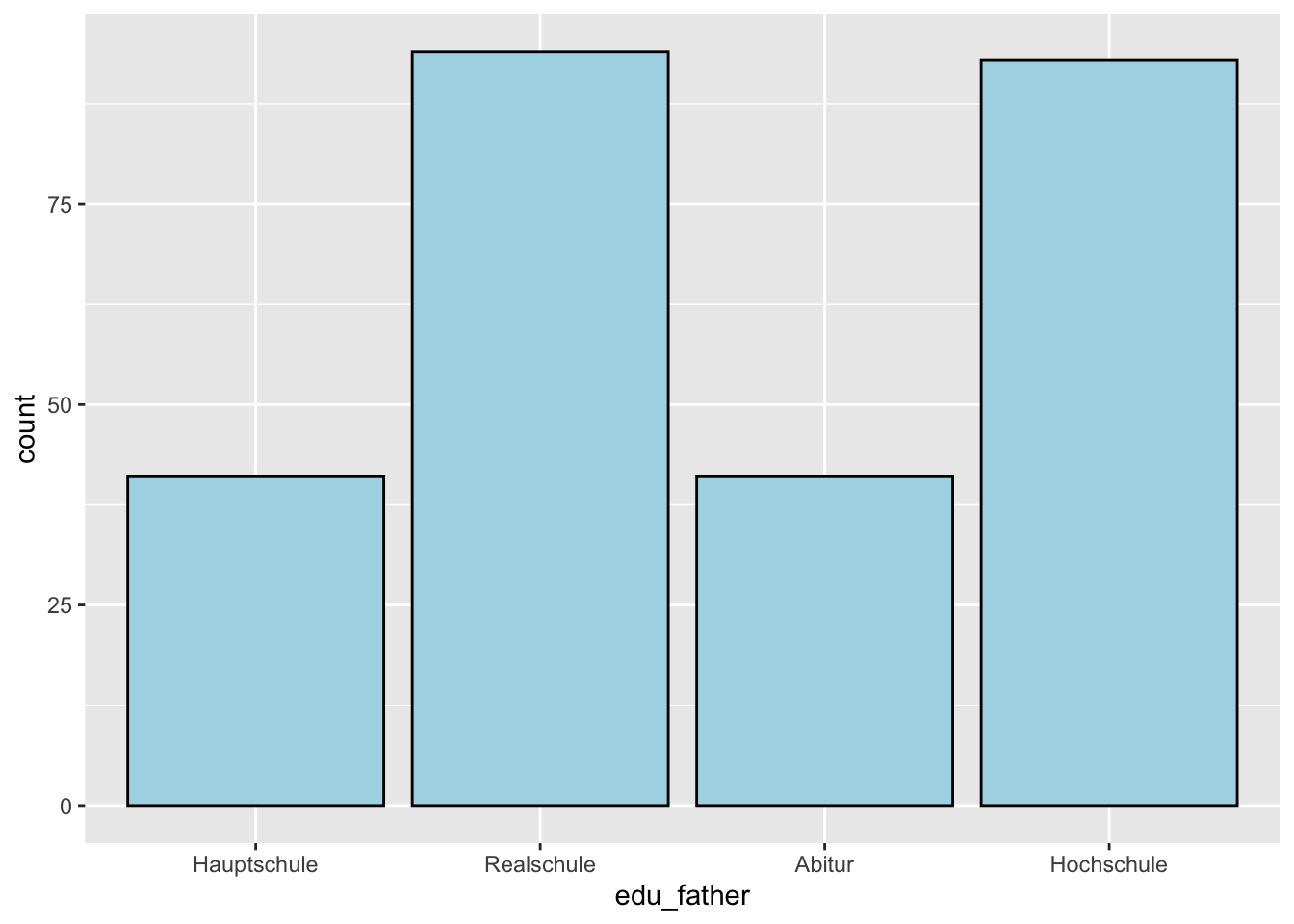
If we do not use fill = 'lightblue', color = 'black' within the aes() function, then these arguments are not considered a grouping statement. For instance, we can just color all elements light blue with fill = 'lightblue'.
For an overview of the possible color names, use the colors() function. There are 657 colors, of which we are showing here only 15 that are randomly sampled with sample(15):
colors() %>% sample(15)## [1] "tomato3" "navajowhite4" "violet" "gray78"
## [5] "darkseagreen4" "grey1" "snow2" "grey66"
## [9] "darkseagreen" "lightskyblue4" "lightblue2" "purple"
## [13] "magenta4" "gray74" "orchid2"Here, too, we can specify a grouping variable, which we use to color code the rectangles.
p <- adolescents %>%
dplyr::select(edu_father, region) %>%
drop_na() %>%
ggplot(aes(x = edu_father, fill = region))
p + geom_bar()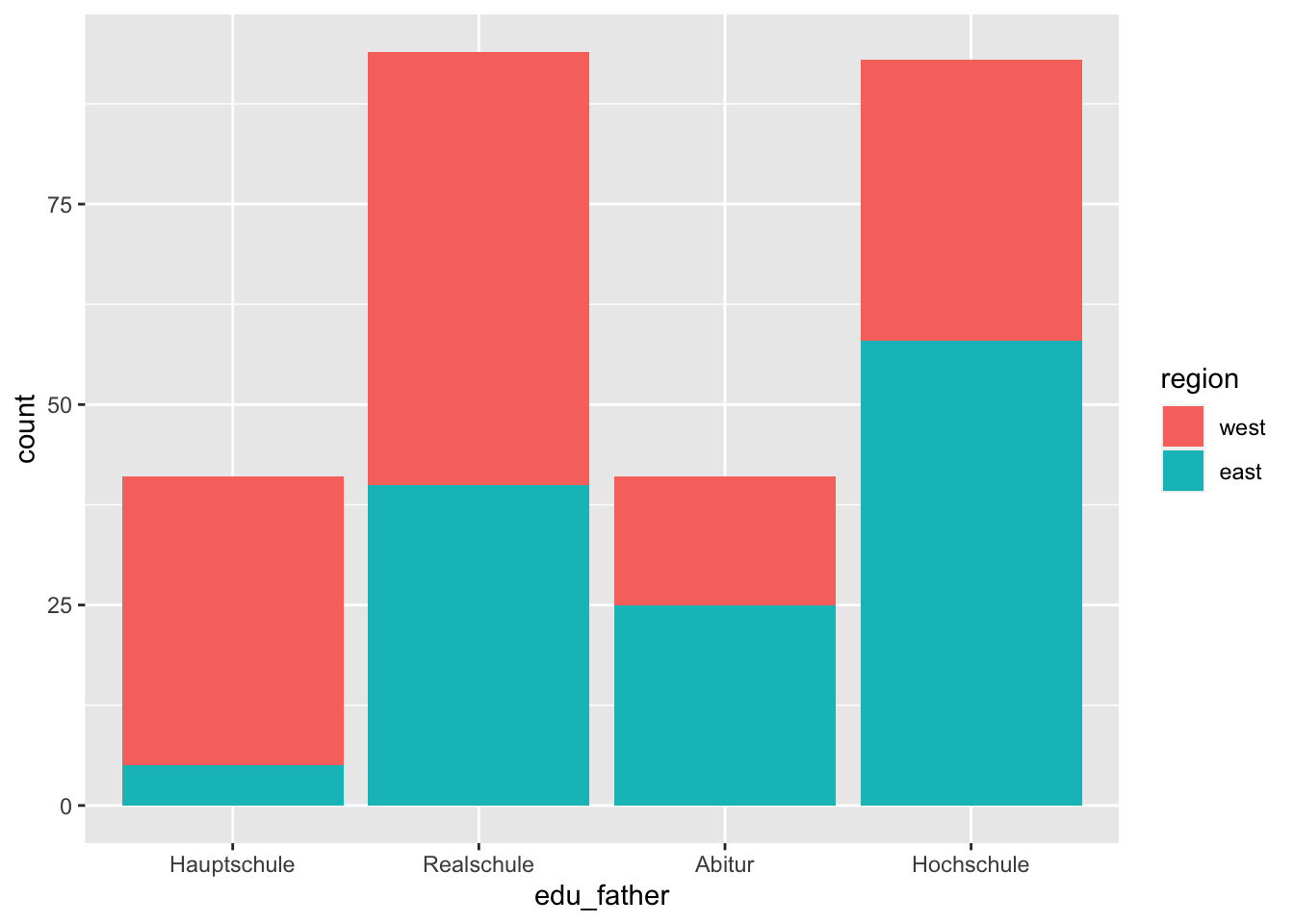
By default, ggplot2 creates a stacked bar chart, i.e. the rectangles are
stacked on top of each other. If this is not desired, we can use the argument
position = "dodge" of the function geom_bar(). This tells the geom_bar()
function that the bars should be drawn next to each other.
p + geom_bar(position = "dodge")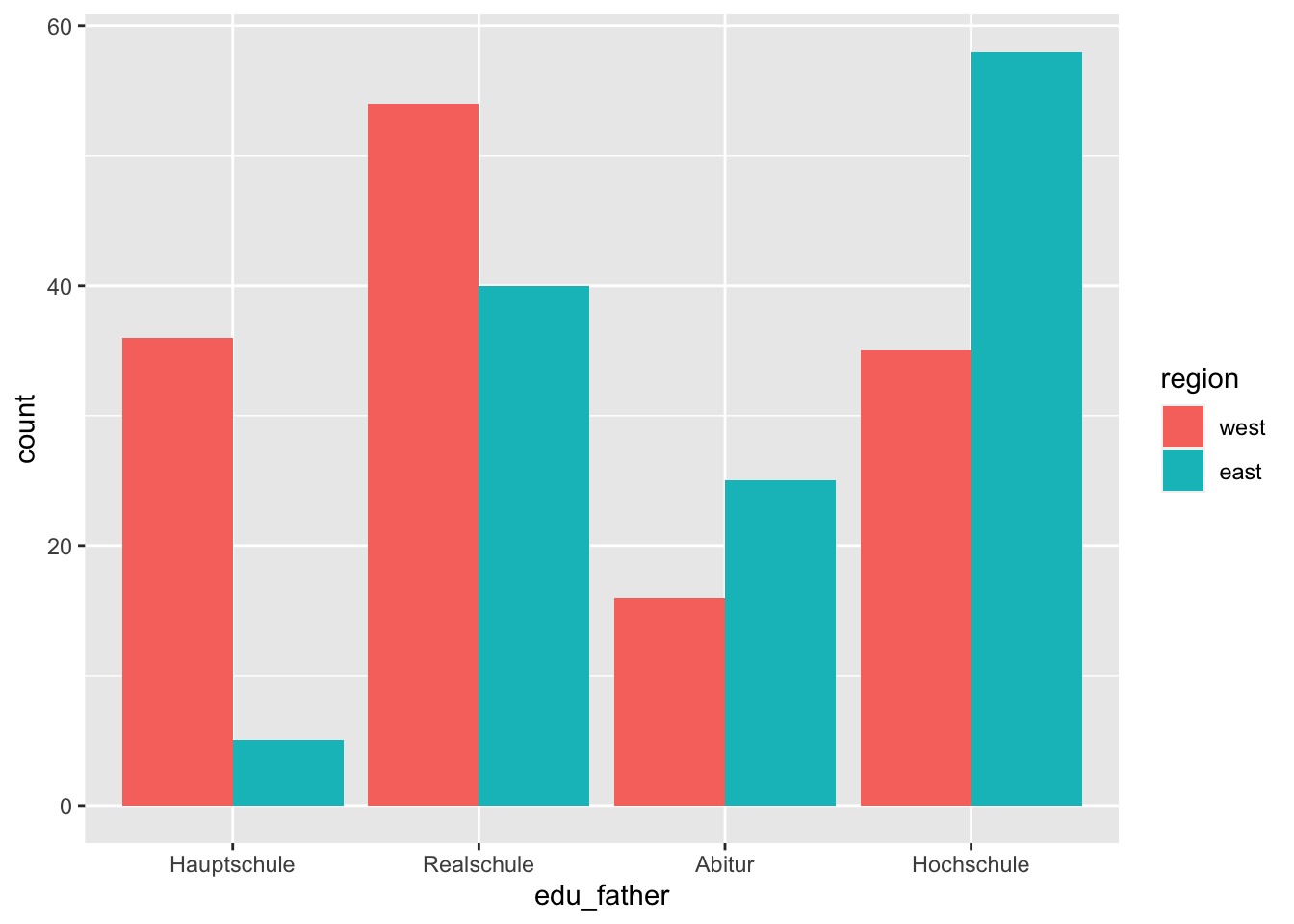
As a third variant we can use position = "identity"; so the bars are drawn on top of each other. Since the rectangle in the background is no longer visible, we use the alpha argument to make the bars transparent.
p + geom_bar(position = "identity", alpha = 0.6)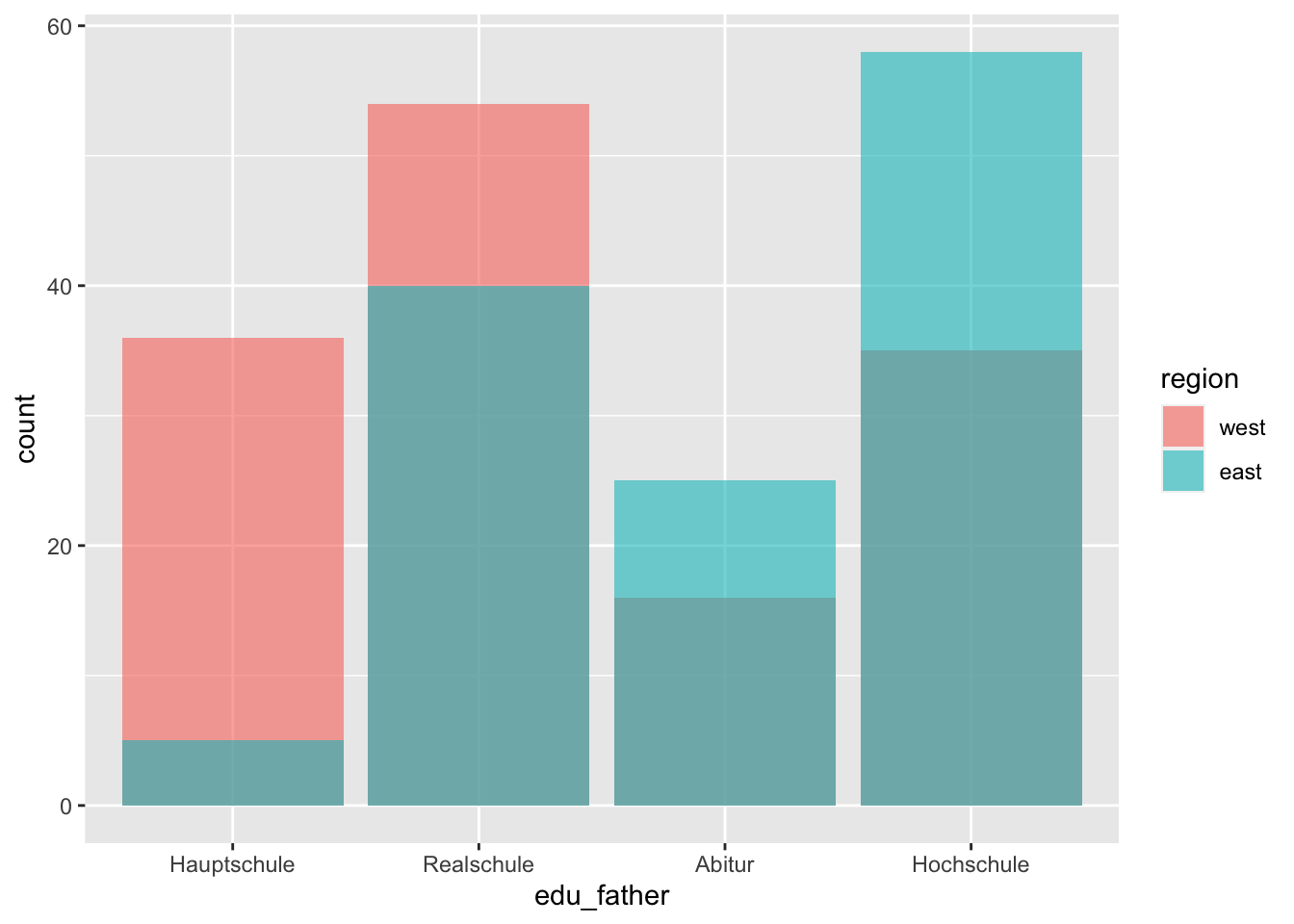
Continuous variable
If the variable that we want to represent graphically is not categorical but
continuous a histogram is the appropriate option; we generate this with the
function geom_histogram(). As an example we consider the psychological stress
symptoms.
A histogram provides a graphical representation of the distribution of a numerical variable. For this purpose, the values of these variables are subdivided into discrete intervals, or bins. On the Y-axis, the frequencies in the respective intervals are then displayed, analogous to a bar chart. The determination of the size of the intervals (bin width) is critical. If we do not specify anything, ggplot2 selects a binwidth itself, but we can also specify it ourselves using the binwidth argument.
p <- adolescents %>%
dplyr::select(stress_psych) %>%
drop_na() %>%
ggplot(mapping = aes(x = stress_psych))
# automatic bin width selection
p + geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.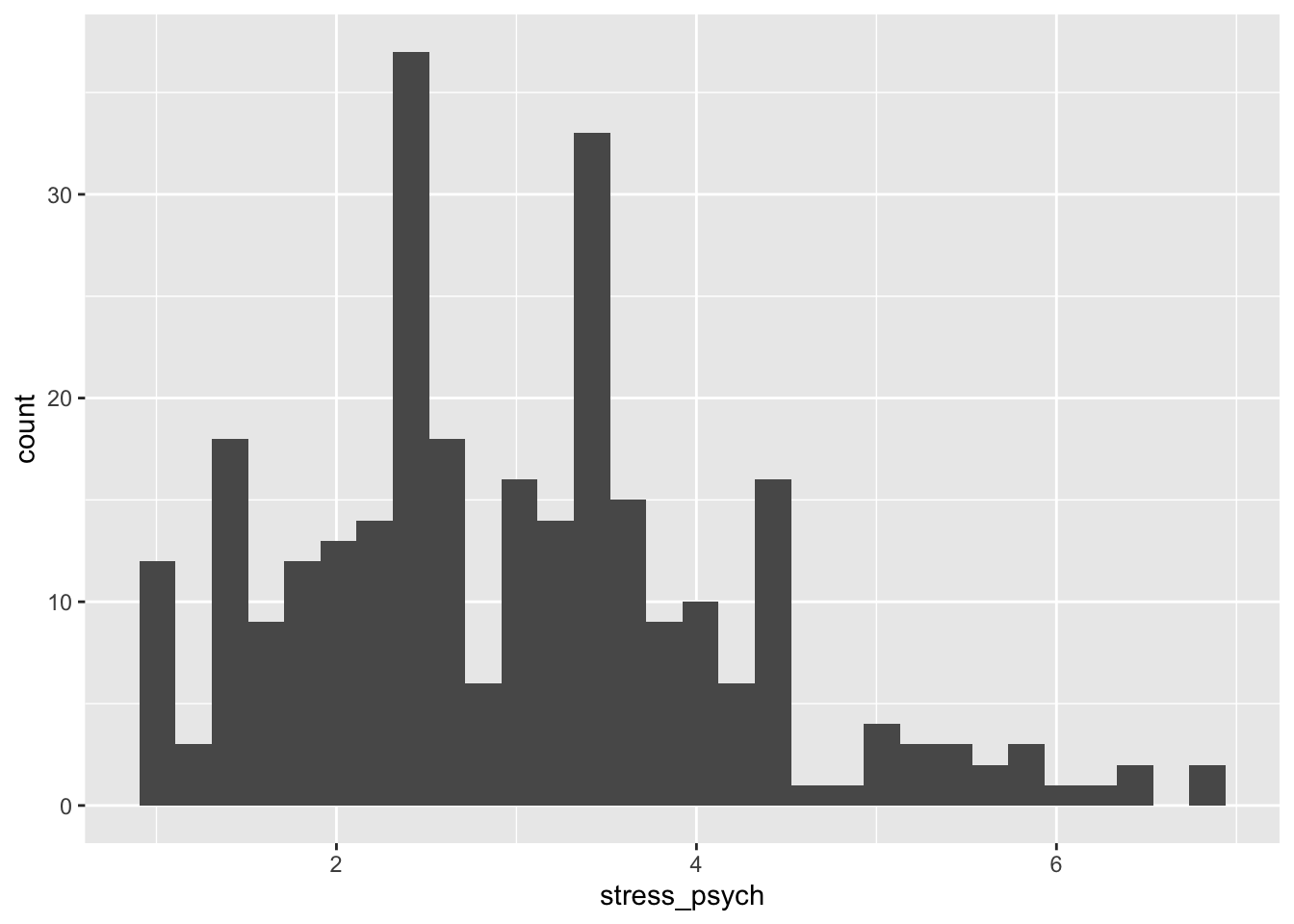
# manual bin width selection
p + geom_histogram(binwidth = 0.5)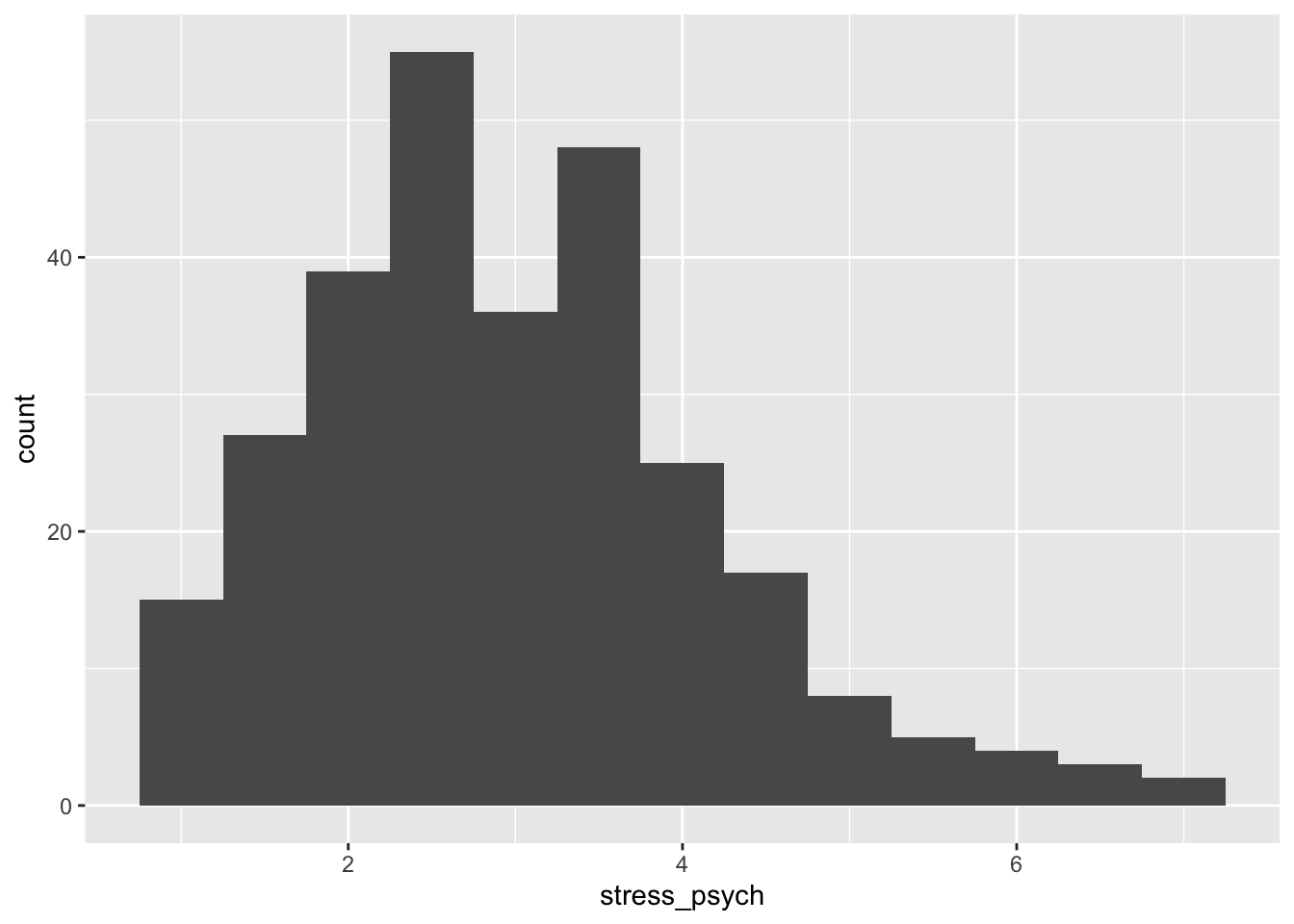
The optimal bin width depends on the scale and variance of the variable and should neither be too fine nor too coarse.
We can also determine the number of bins directly using the bins argument:
p + geom_histogram(bins = 14)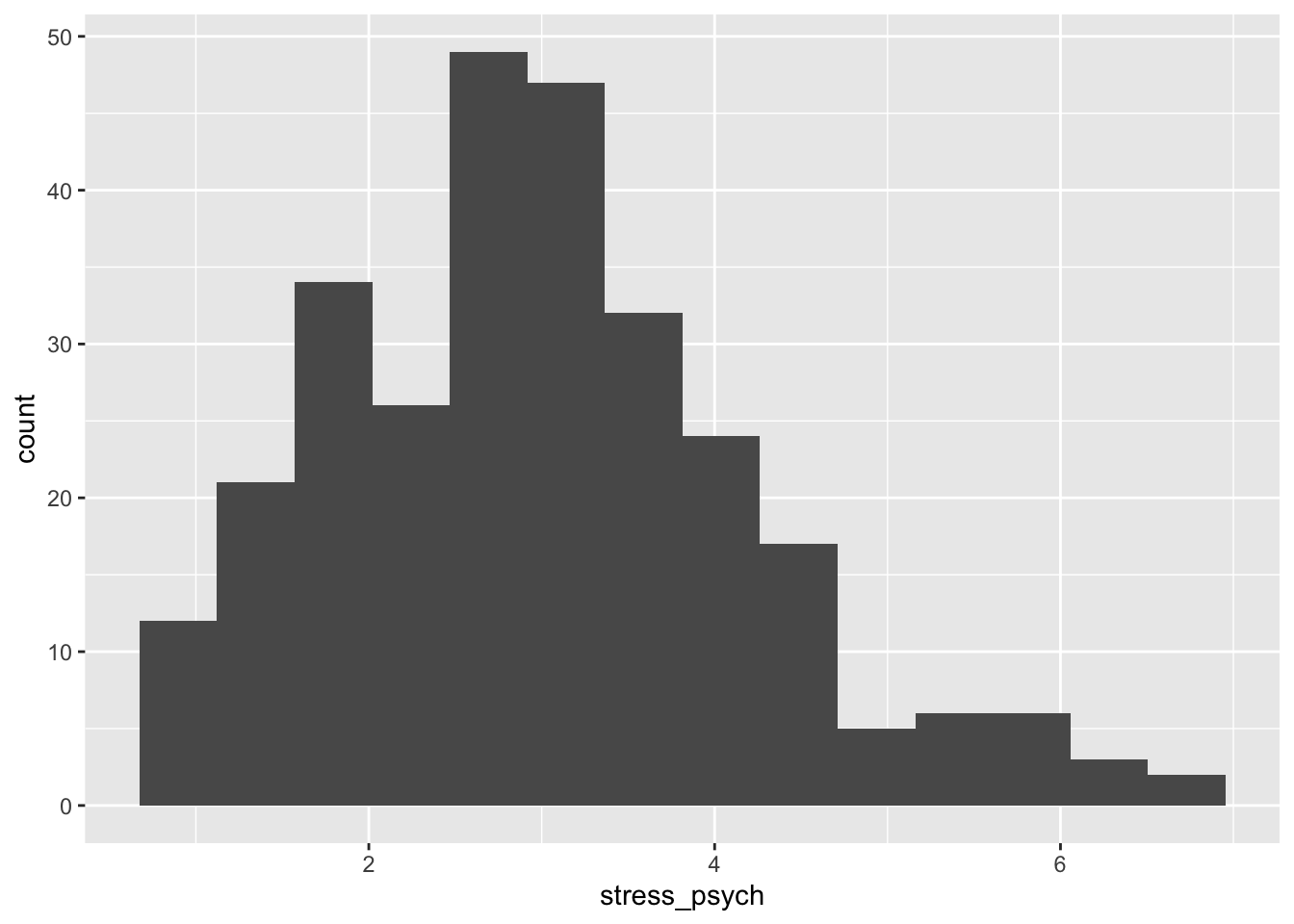
If we want the relative frequencies on the Y axis instead of the absolute ones, we can use aes() function with the y = ..density.. argument.
p <- adolescents %>%
dplyr::select(stress_psych) %>%
drop_na() %>%
ggplot(mapping = aes(x = stress_psych, y = ..density..))
p + geom_histogram(binwidth = 0.5)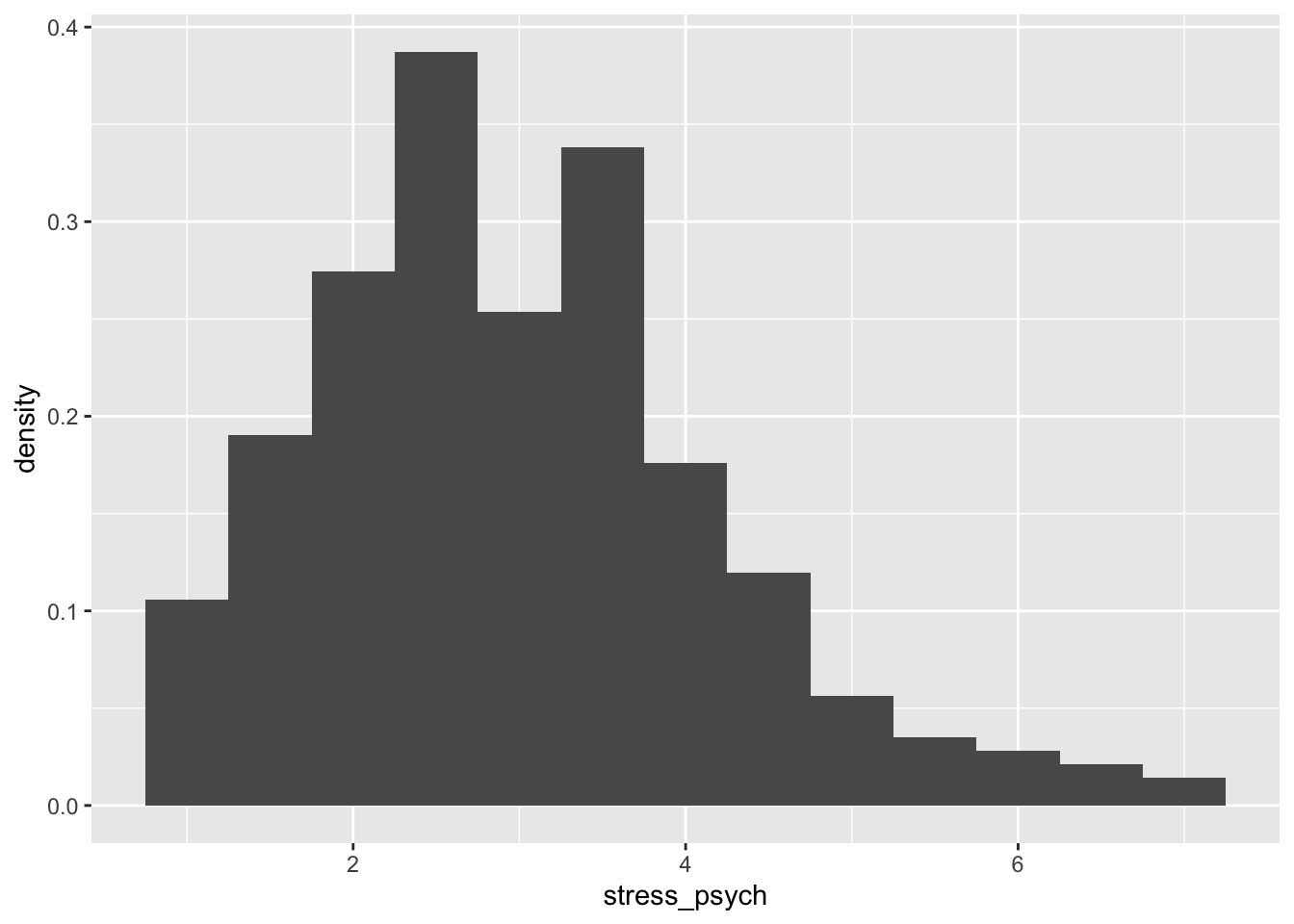
We can use a grouping variable also with histograms:
p <- adolescents %>%
dplyr::select(stress_psych, gender) %>%
drop_na() %>%
ggplot(mapping = aes(x = stress_psych, fill = gender))
p + geom_histogram(binwidth = 0.5)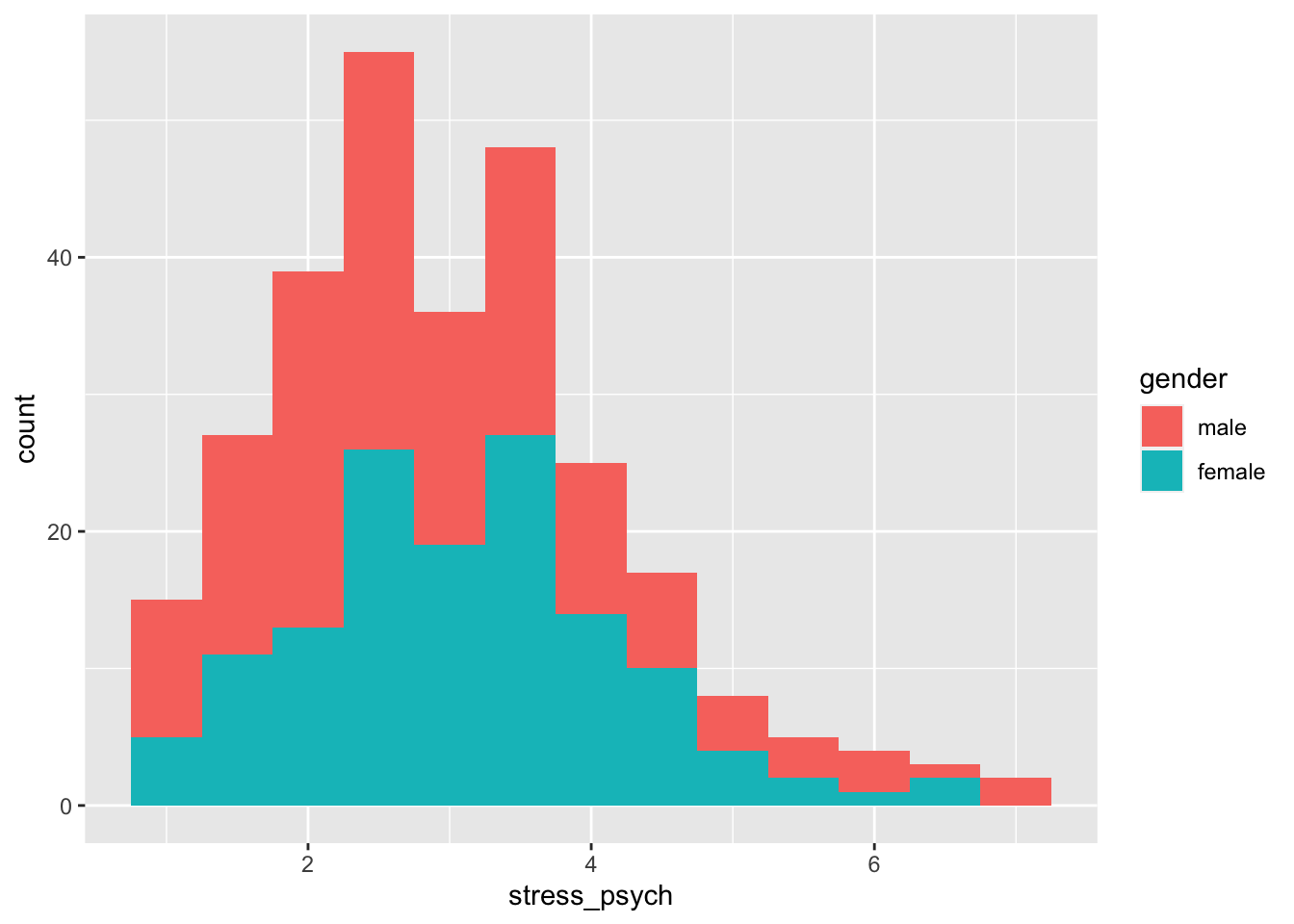
As with the bar chart, the histograms are stacked on top of each other. If we
want them separately in the same space of the plot, we use position = "identity" together with the transparancy argument alpha.
p <- adolescents %>%
dplyr::select(stress_psych, gender) %>%
drop_na() %>%
ggplot(mapping = aes(x = stress_psych, fill = gender))
p + geom_histogram(binwidth = 0.5,
position = "identity",
alpha = 0.6)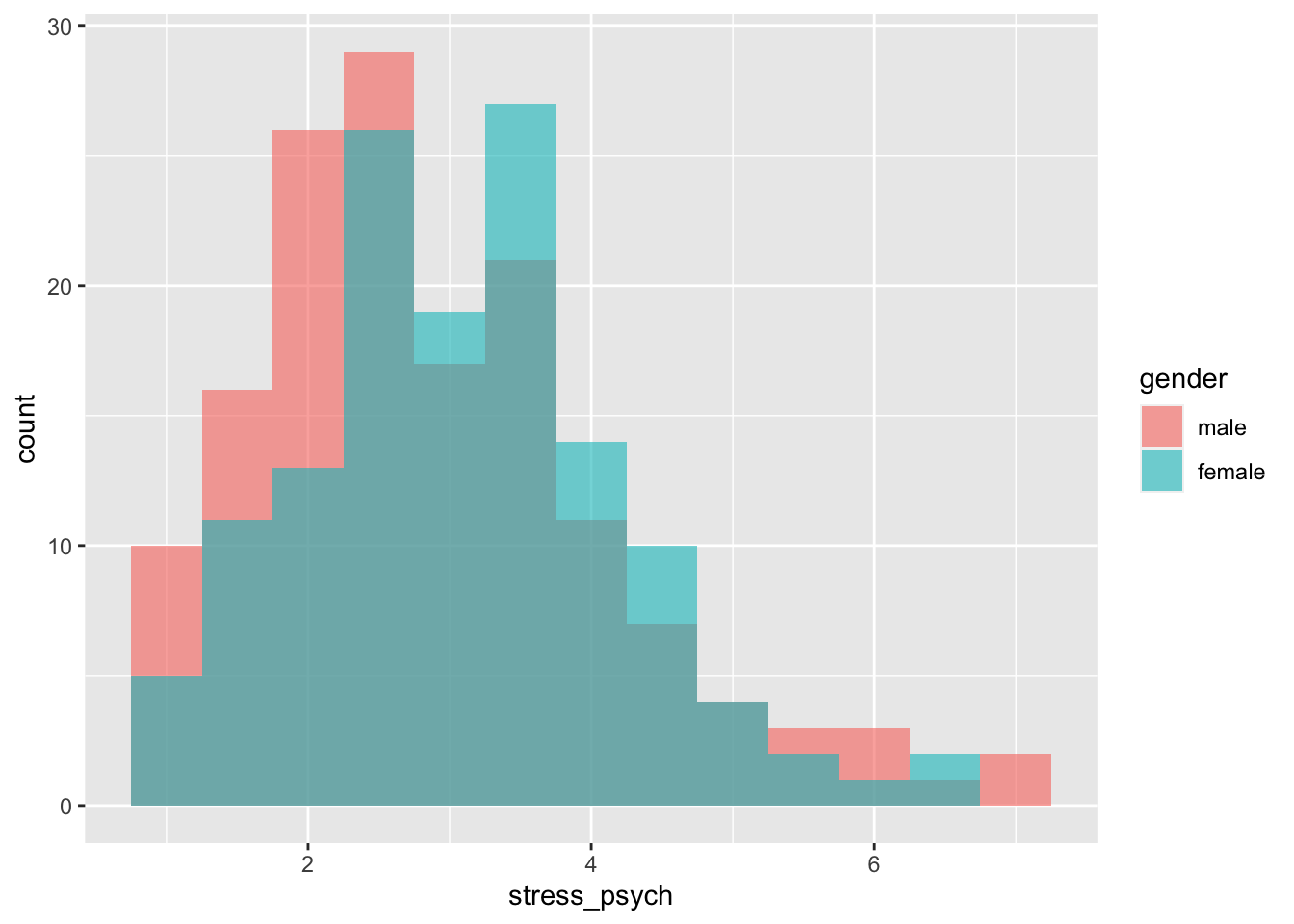
Next to each other is also possible:
p <- adolescents %>%
dplyr::select(stress_psych, gender) %>%
drop_na() %>%
ggplot(mapping = aes(x = stress_psych, fill = gender))
p + geom_histogram(binwidth = 0.5,
position = "dodge")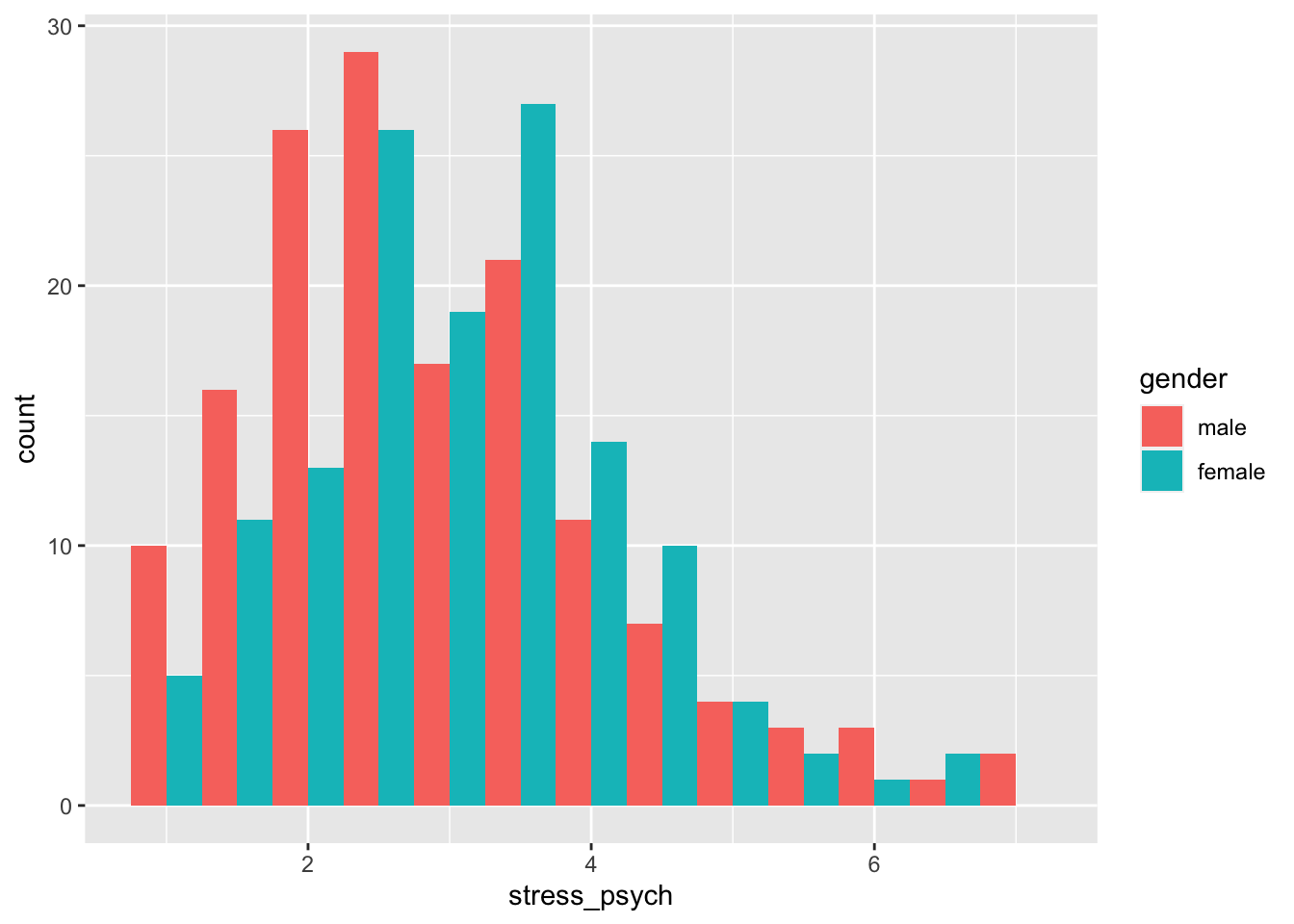
6.4.2 Two variables
Now we display two variables of a data set together. Again, the possible geoms depend on the data type of the variables.
X and Y continuous
If both variables are continuous, we can show their relationship using a scatterplot or a line graph. We use the functions geom_point(), or geom_line().
As an example we want to visualize the relation between psychological stress symptoms and life satisfaction.
p <- adolescents %>%
dplyr::select(stress_psych, lifesat_overall) %>%
drop_na() %>%
ggplot(mapping = aes(x = stress_psych, y = lifesat_overall))
p + geom_point(size = 2, alpha = 0.4, color = "purple")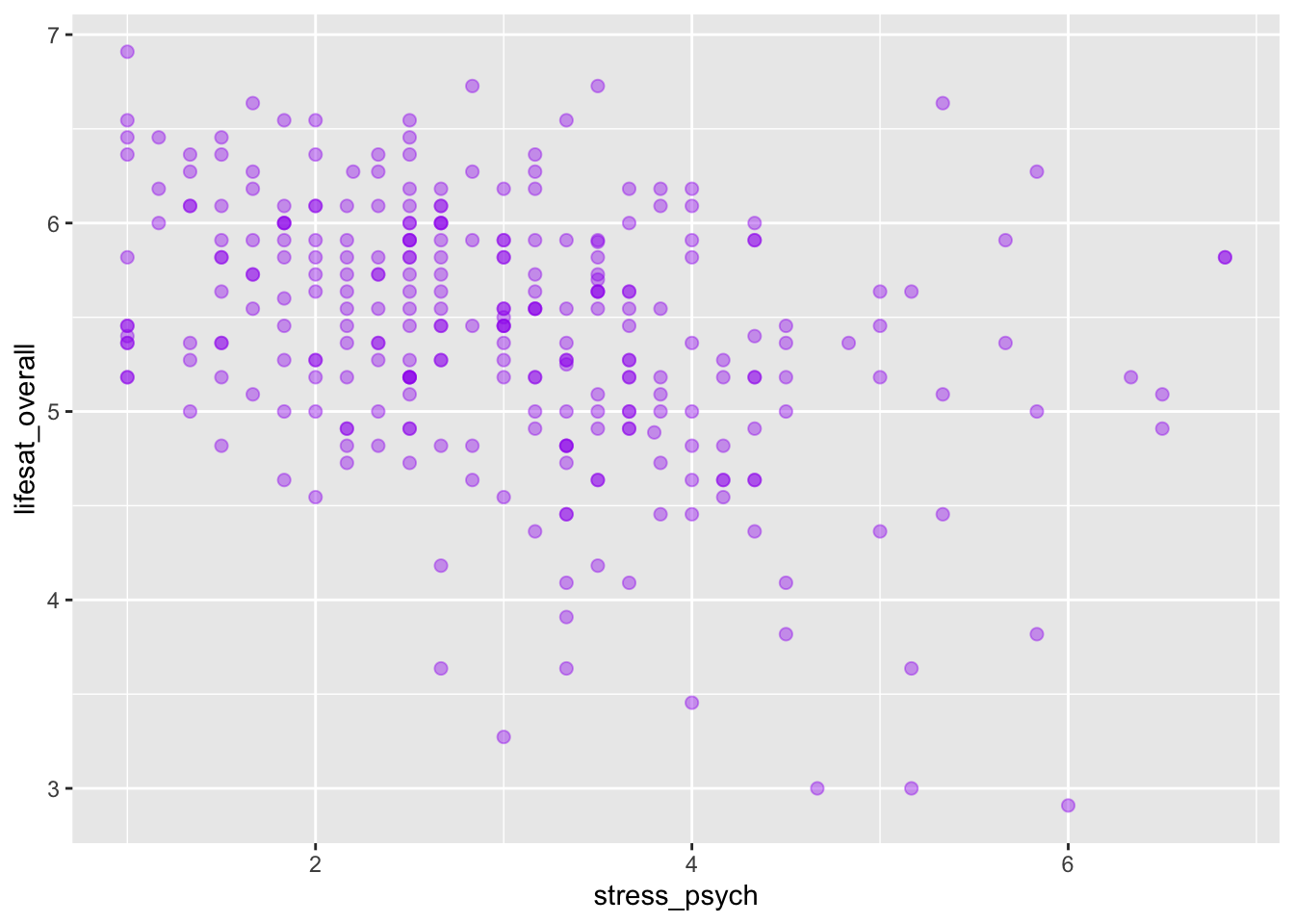
Grouping based on a categorical variable works here as well. We use both the color and the shape of the dots to better distinguish the categories.
p <- adolescents %>%
dplyr::select(stress_psych, lifesat_overall, gender) %>%
drop_na() %>%
ggplot(mapping = aes(x = stress_psych,
y = lifesat_overall,
color = gender,
shape = gender))
p + geom_point(size = 2, alpha = 0.6)
Let’s also add linear regression lines:
p + geom_point(size = 2, alpha = 0.6) +
geom_smooth(aes(linetype = gender),
method = "lm", se = FALSE)## `geom_smooth()` using formula 'y ~ x'
With se = TRUE (default) confidence bands for the regression line (predicted values) are added.
X categorical and Y continuous
If one of the variables is categorical, then instead of using it as a grouping variable, we can represent it on one axis.
We have actually already seen an example of this in the introductory part to this chapter where we displayed the distribution of stress_psych (continuous Y) separately for the levels of the factor gender (categorical X) used the geom_boxplot() and
geom_violin() functions. Let us demonstrate this again starting with the adolescents data frame and (as a shortcut) without the intermediary definition of a plot object:
adolescents %>%
select(gender, stress_psych) %>%
drop_na() %>%
ggplot(mapping = aes(x = gender,
y = stress_psych)) +
geom_boxplot(aes(color = gender)) +
geom_jitter(width = 0.1, alpha = 0.4)
X and Y categorical
Finally, the variables can be categorical on both the X and Y axes. In this case
it would be useful to plot the joint frequencies using the function
geom_count().
As an example we want to consider the joint frequency distribution of the education of the father and the education of the mother.
p <- adolescents %>%
dplyr::select(starts_with("edu")) %>%
drop_na() %>%
ggplot(aes(x = edu_father,
y = edu_mother))
p + geom_count(color = "purple")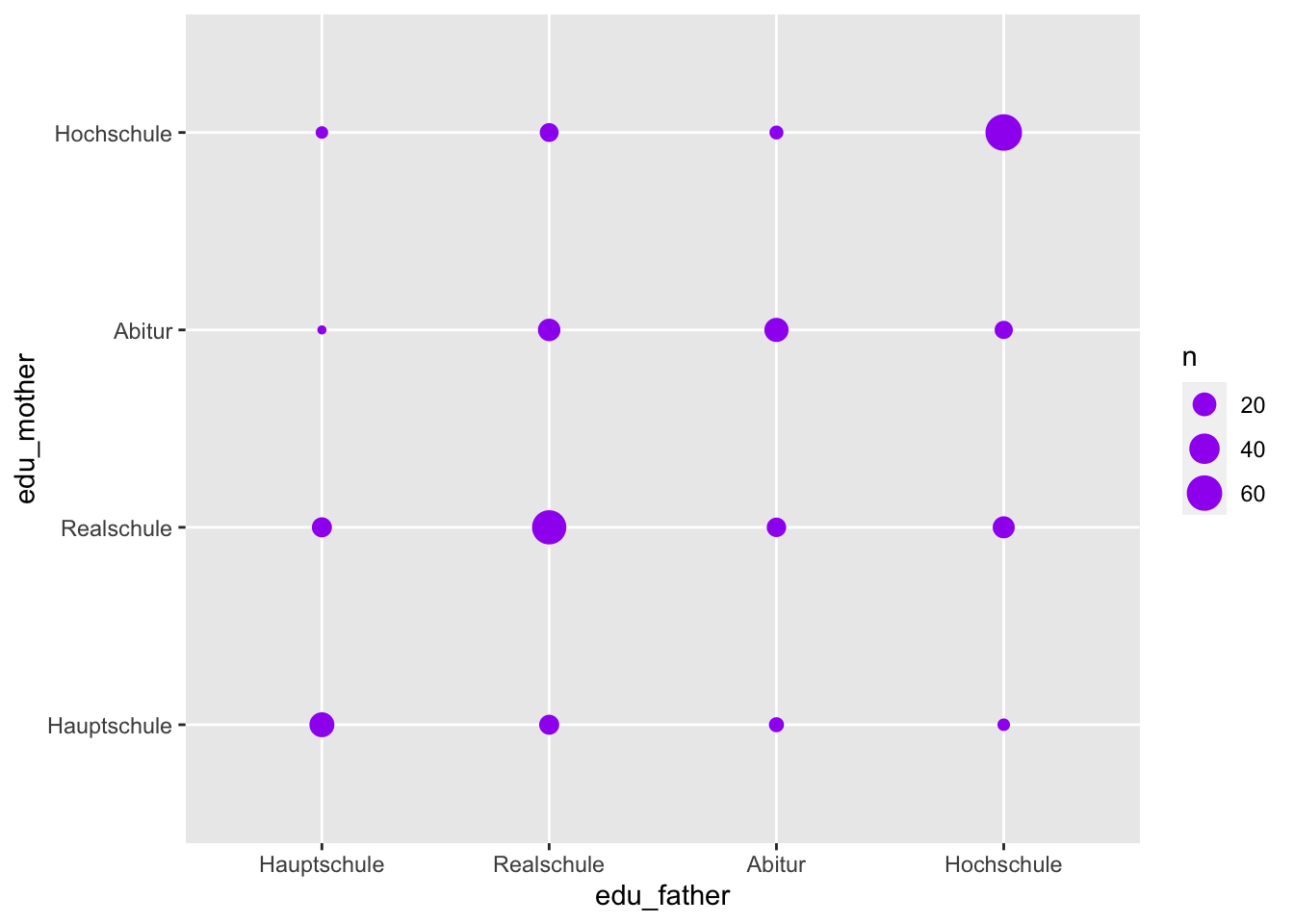
geom_count() counts the joint frequencies of the categories of the two variables and displays them as the diameter of the points.
We can obtain the frequency table using the table() function:
table(adolescents$edu_father, adolescents$edu_mother)##
## Hauptschule Realschule Abitur Hochschule
## Hauptschule 23 12 2 3
## Realschule 12 55 17 10
## Abitur 5 11 21 4
## Hochschule 3 16 9 65The table is upside-down relative to the graph. The high frequencies in the diagonal represent a kind of “educational homogamy” in this dataset.
6.5 Facets
Previously, we used grouping variables to create different colors/shapes/lines for the categories of the grouping variable within a plot. Sometimes this is too confusing.
For example, if we want to create a histogram of grades at each stage of the mother’s education, then the graph would be completely overloaded.
p <- adolescents %>%
dplyr::select(grade_overall, edu_mother) %>%
drop_na() %>%
ggplot(mapping = aes(x = grade_overall,
fill = edu_mother))
p + geom_histogram(binwidth = 0.8,
position = "dodge")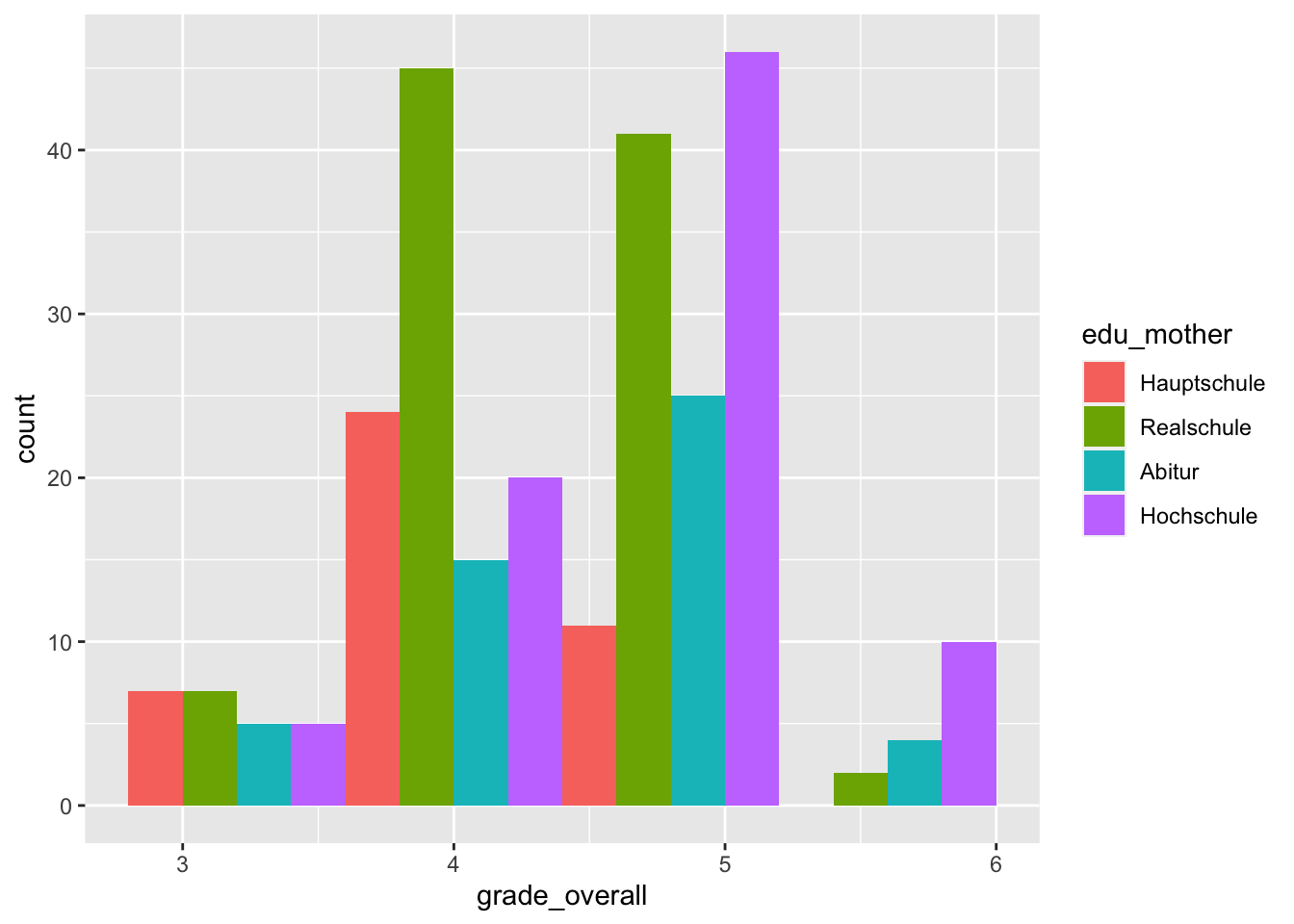
An obvious solution would be to display the histograms for the mother’s education levels in separate graphics.
This is exactly what we can do with the functions facet_wrap() and facet_grid().
With facet_wrap() we create a graphic for each category of the grouping variable:
p <- adolescents %>%
dplyr::select(grade_overall, edu_mother) %>%
drop_na() %>%
ggplot(mapping = aes(x = grade_overall,
fill = edu_mother)) +
facet_wrap(~ edu_mother)
p + geom_histogram(binwidth = 0.8)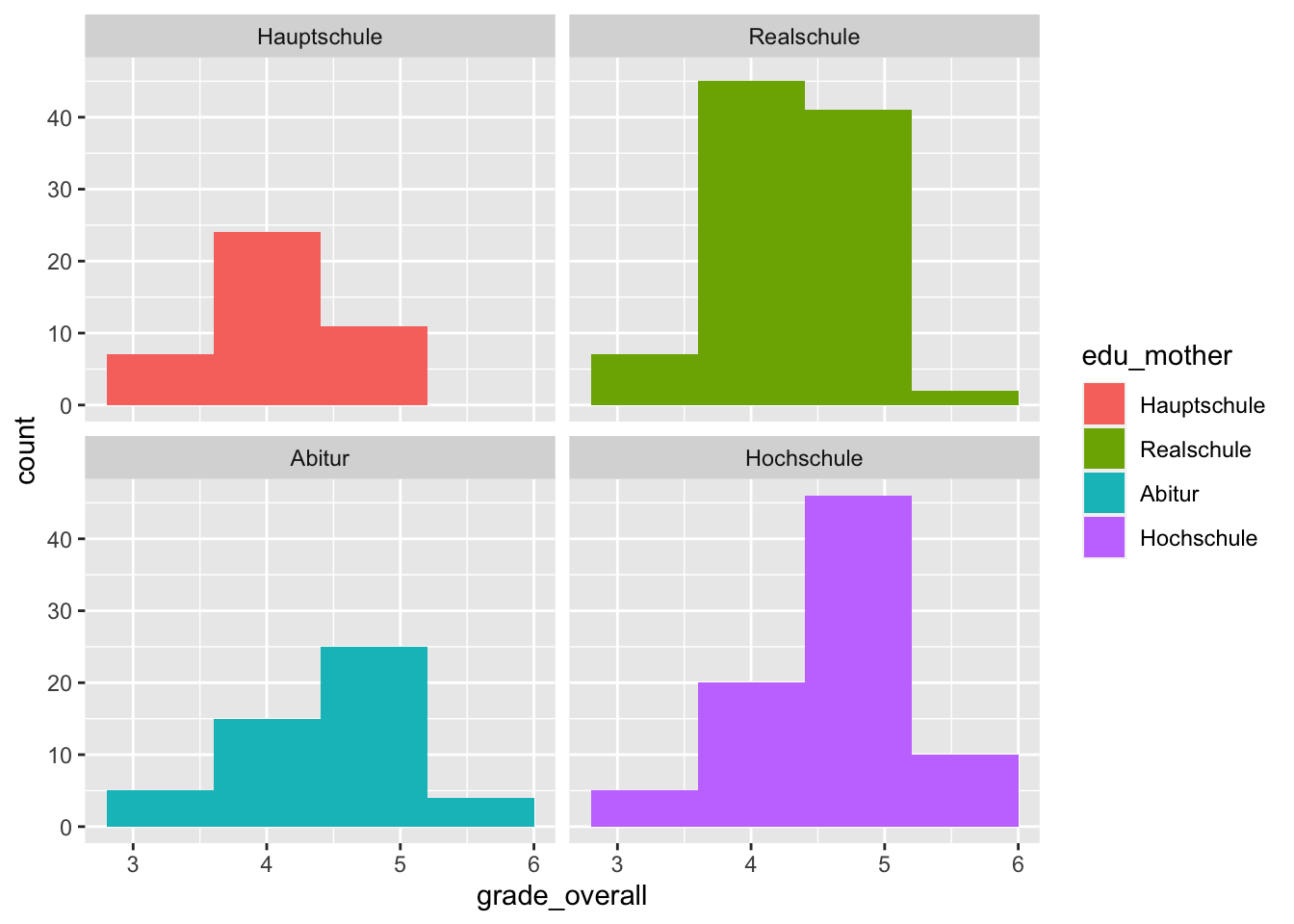
If we have two grouping variables, we can create a raster with facet_grid().
p <- adolescents %>%
dplyr::select(grade_overall, edu_mother, edu_father) %>%
drop_na() %>%
ggplot(mapping = aes(x = grade_overall)) +
facet_grid(edu_mother ~ edu_father)
p + geom_histogram(binwidth = 0.8,
fill = 'steelblue4')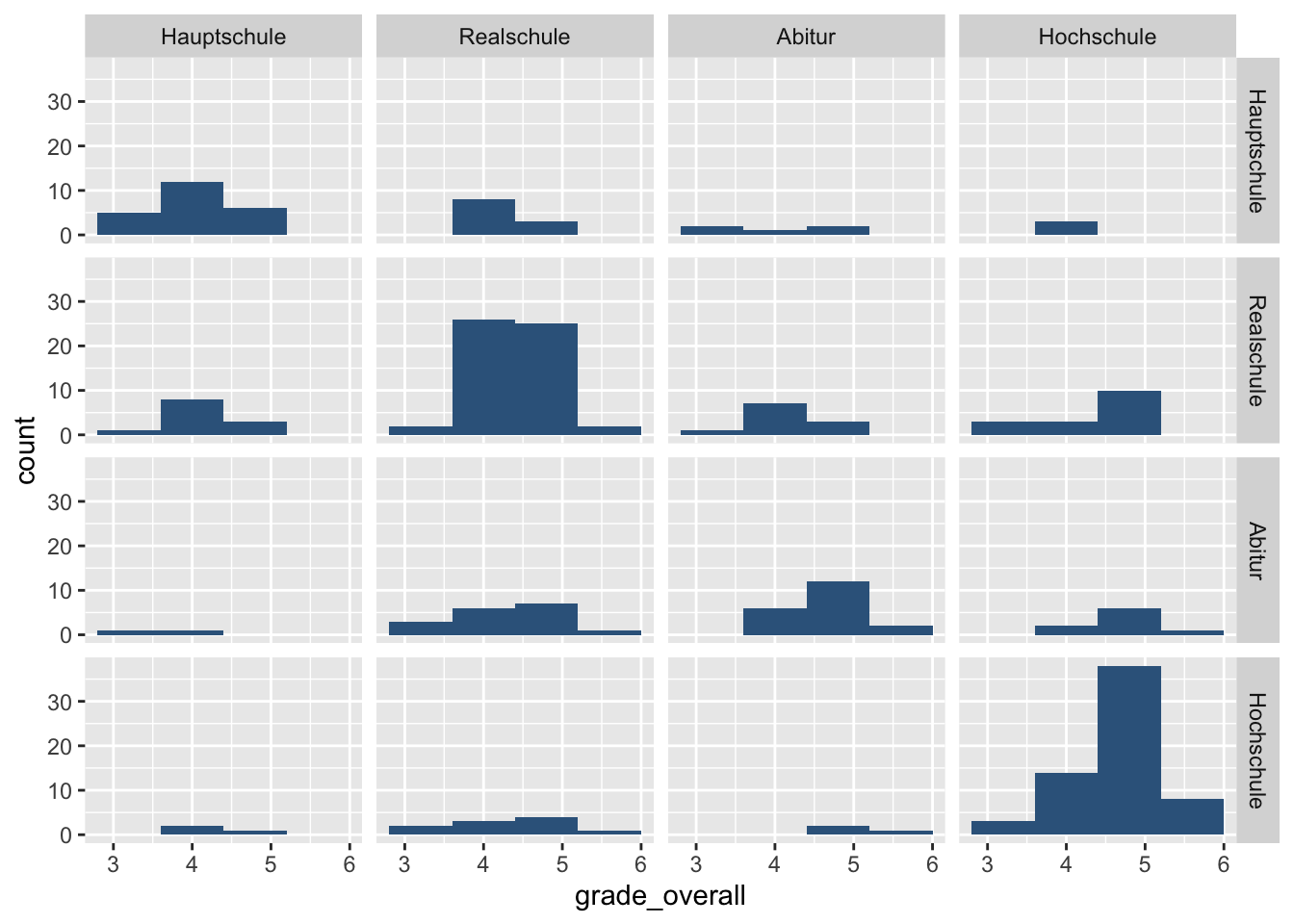 Here the levels of
Here the levels of edu_mother are shown in the rows, and the levels of edu_father in the columns.
6.6 Colors and themes
So far, we have used the default colour palette. However, the standard colours are unsuitable for color blind people. There are many color palettes that we could use. One particularly attractive colour scheme is the viridis colour palette.
We will use the palette as follows:
to fill in shapes we use
scale_fill_viridis_d()orscale_fill_viridis_c(), depending on whether the variable is discrete or continuous.for lines and dots we use
scale_color_viridis_d()orscale_color_viridis_c()
As an example, we again plot the relationship between stress_psych andleben_gesamt, this time with our own color palette.
p <- adolescents %>%
dplyr::select(ID, gender, stress_psych, lifesat_overall) %>%
drop_na() %>%
ggplot(aes(x = stress_psych,
y = lifesat_overall,
color = gender,
shape = gender))
p + geom_jitter(size = 3, alpha = 0.9) +
scale_color_viridis_d()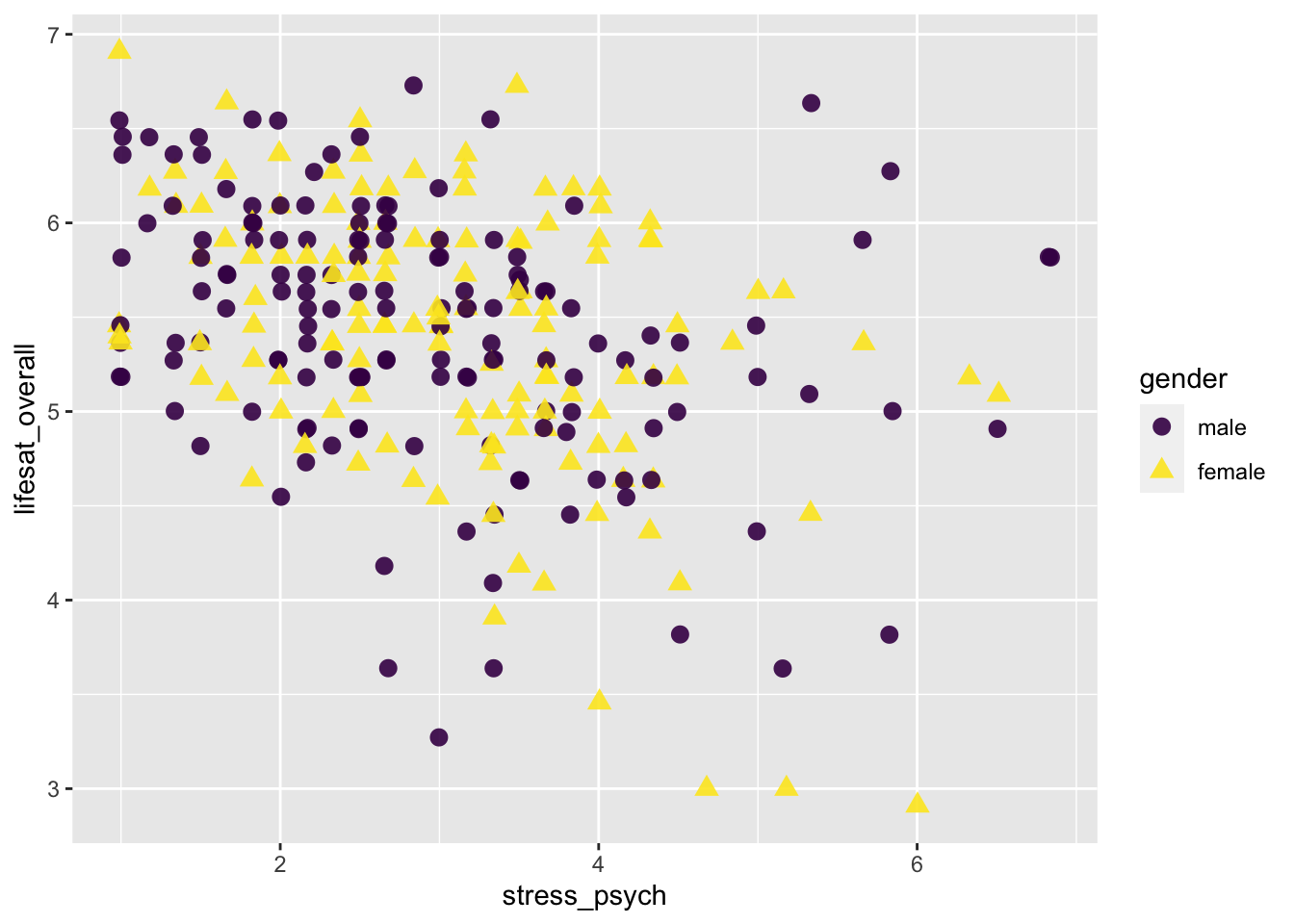
We can assign the colors also ‘manually’:
p + geom_jitter(size = 3, alpha = 0.9) +
scale_colour_manual(values = c("pink2", "steelblue3"))
Many people do not really like the gray background that ggplot2 automatically
chooses. The easiest way to change this is to define a theme. There are two themes that have a white background: theme_bw() and theme_classic().
These two in turn differ in that theme_classic() does not draw gridlines,
and only the left and bottom axes.
p <- adolescents %>%
dplyr::select(stress_psych, lifesat_overall, gender) %>%
drop_na() %>%
ggplot(aes(x = stress_psych,
y = lifesat_overall,
color = gender))
p + geom_jitter(size = 3) +
scale_color_manual(values = c("yellow2", "black")) +
theme_bw()
p <- adolescents %>%
dplyr::select(stress_psych, lifesat_overall, gender) %>%
drop_na() %>%
ggplot(aes(x = stress_psych,
y = lifesat_overall,
color = gender,
shape = gender))
p + geom_jitter(size = 2.5, alpha = 0.9) +
scale_color_viridis_d() +
theme_classic()
There are quite a few packages on CRAN that provide ggplot2 themes.
6.7 Plot labels
Now we can also change the labels of the X / Y axes with xlab() and ylab(),
and give the plot a title with the ggtitle() function. With the function
labs() we can additionally change the title of the legend.
Finally, we also want to increase the font size, as the often seems
too small. We do this with the argument base_size = FONT SIZE of the theme_*
functions.
p <- adolescents %>%
dplyr::select(stress_psych, lifesat_overall, gender) %>%
drop_na() %>%
ggplot(aes(x = stress_psych,
y = lifesat_overall,
color = gender,
shape = gender))
p + geom_jitter(size = 2.5, alpha = 0.9) +
scale_color_viridis_d() +
theme_classic(base_size = 14) +
ggtitle("Psychological Stress and Life Satisfaction") +
xlab("Psychological Stress")+
ylab("Life Satisfaction") +
# title of both the color and the shape legend is "Gender"
labs(color = "Gender",
shape = "Gender")
6.8 Saving plots
Of course, if we made a nice graph or plot, we want to save it. We can do this
with the function ggsave(). The function takes as arguments the file name, the
name of the plot object and other properties, such as the desired height and
width of the plot. These may expressed in “cm” using the argument units = "cm". To save the graph, we must have assigned our finished ggplot2 object to
a variable:
p <- adolescents %>%
dplyr::select(stress_psych, lifesat_overall, gender) %>%
drop_na() %>%
ggplot(mapping = aes(x = stress_psych,
y = lifesat_overall,
color = gender,
shape = gender))
my_plot <- p + geom_jitter(size = 2.5, alpha = 0.9) +
scale_color_viridis_d() +
theme_classic(base_size = 14) +
ggtitle("Psychological Stress and Life Satisfaction") +
xlab("Psychological Stress")+
ylab("Life Satisfaction") +
labs(color = "Gender") +
guides(shape = "none")my_plot
my_plot can now be saved:
ggsave(filename = "my_plot.png",
plot = my_plot)## Saving 7 x 5 in image