Das Kontexteffekt-Modell ist eine Variante des Intercept-as-Outcome-Modells. Der Level-2-Prädiktor ist hier ein auf Gruppenebene aggregierter Level-1-Prädiktor.
In unserem Beispiel ist der Level-2-Prädiktor die durchschnittliche Erfahrung der Mitarbeitenden pro Firma, also die in Kapitel 1 gebildete Firmenmittelwerts-Variable exp_groupmean. Der Effekt dieser Variablen wird gemeinsam mit der gruppenzentrierten Erfahrung exp_centered untersucht. Zusätzlich zu der Annahme, dass die individuelle Erfahrung mit einem höheren Lohn einhergeht, nehmen wir nun an, dass sich auch die durchschnittliche Erfahrung der Mitarbeitenden einer Firma auf den durchschnittlichen Lohn in einer Firma auswirkt.
Im Kontexteffekt-Modell wird häufig kein Random Slope zugelassen, weil man sich auf die Fixed Effects auf beiden Untersuchungsebenen konzentriert und ausserdem die Varianzerklärung durch einen Level-2-Prädiktor nur mit Hilfe dieses Modells berechnet werden kann (s.u.). Man könnte aber im Prinzip auch hier einen Random Slope von exp_centered zulassen. Wir verzichten hier darauf und verweisen diesbezüglich auf das Allgemeine Intercept-as-Outcome-Modell weiter unten.
\(z_{i}\) steht hier für den Gruppenmittelwert \(\bar x_{\bullet i}\) der experience-Variable (d.h. für die in exp_groupmean gespeicherten Werte). Zur Veranschaulichung lassen wir uns diese Gruppenmittelwerte pro Firma mit Hilfe von distinct() ausgeben (in aufsteigender Reihenfolge):
Die durchschnittliche Erfahrung der Mitarbeitenden pro Firma variiert zwischen \(4.02\) und \(6.37\) Jahren.
Modell berechnen
# Fitten und abspeichern des Modellscontext.model <-lmer(salary ~ exp_centered + exp_groupmean + (1| company),data = df, REML =TRUE)# Durch das Modell vorhergesagte Werte abspeicherndf$context.model.preds <-predict(context.model)# Output anschauensummary(context.model)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: salary ~ exp_centered + exp_groupmean + (1 | company)
Data: df
REML criterion at convergence: 1865.5
Scaled residuals:
Min 1Q Median 3Q Max
-2.7991 -0.6796 0.0043 0.6008 3.8752
Random effects:
Groups Name Variance Std.Dev.
company (Intercept) 0.623 0.7893
Residual 1.185 1.0884
Number of obs: 600, groups: company, 20
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 4.77925 1.38736 18.00000 3.445 0.00289 **
exp_centered 0.53188 0.02735 579.00000 19.446 < 2e-16 ***
exp_groupmean 0.76264 0.26499 18.00000 2.878 0.01001 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr) exp_cn
exp_centerd 0.000
exp_groupmn -0.991 0.000
Der Effekt von exp_centered ist mit \(\hat\gamma_{10} = 0.532\) sehr ähnlich wie im Random-Intercept-Modell. Der Effekt von exp_groupmean ist noch grösser - jedes Jahr durchschnittliche Erfahrung, die die Angestellten einer Firma mehr haben als die Angestellten einer anderen Firma, lässt den vorhergesagten Salary-Wert der Angestellten dieser Firma (und damit den Intercept \(\hat\beta_{0i}\)) um \(\hat\gamma_{01} = 0.763\) Einheiten (ca. 763 CHF) steigen.
Visualisierung des Modells
Die folgenden Plots spielen sich nur auf der Firmenebene (Level-2) ab. Der erste Plot zeigt die Abweichungen (Level-2-Residuen \(\upsilon_{0i}\)) der einzelnen Firmen-Intercepts vom Gesamtmittelwert der Intercepts (\(\hat\gamma_{00}\)) im Intercept-Only-Modell. Die Durchschnittslöhne der Firmen unterscheiden sich stark vom Mittelwert der Löhne aller Firmen (hellblaue Punkte). Zur Veranschaulichung sind ausserdem die (ohne Shrinkage geschätzten) empirischen salary-Mittelwerte pro Firma im Plot dargestellt (kleine schwarze Punkte).
Beim zweiten Plot kommt der Level-2 Prädiktor exp_groupmean (also die durchschnittliche Erfahrung, die die Angestellten jeder Firma haben) ins Spiel. Es zeigt sich, dass sich die exp_groupmean zwischen den Firmen unterscheidet (vgl. Deskriptivstatistik weiter oben), und dass exp_groupmean positiv mit den Intercepts des Intercept-Only-Modells korreliert (Steigung der Geraden = \(\hat\gamma_{01} = 0.763\)). Durch den Prädiktor nimmt die Abweichung der Gruppenmittelwerte von dem vorhergesagten Wert ab: Im Vergleich zum ersten Plot sind die Firmen-Punkte näher an der Linie, Teile der Level-2-Residuen konnten also durch den Level-2-Prädiktor erklärt werden.
Daraus leitet sich auch der Name von Modell 4 her: Der Prädiktor auf Level-2 (exp_groupmean) sagt den (gruppenspezifischen) Intercept vorher (“Intercept-as-Outcome”).
Code
# Modell fittenintercept.only.model <-lmer(salary ~1+ (1| company), data = df, REML =TRUE)# Daten vorbereitenplot_df_intonly <- df |>mutate(intercept_only_predictions =predict(intercept.only.model), # level 1 predictionsintercept_only_intercept =fixef(intercept.only.model) ) |># overallgroup_by(company) |>summarise(overall =unique(intercept_only_intercept), # fixef interceptprediction =unique(intercept_only_predictions), # fixef intercept + ranef interceptobserved =mean(salary), # actual mean of salary per companyoverall_to_prediction = prediction - overall, # ranef interceptcompany =unique(company), # name of companyexp_groupmean =mean(experience) )# Plottenintercept_only_plot <-ggplot(aes(x = exp_groupmean, y = prediction),data = plot_df_intonly) +geom_segment(aes(xend = exp_groupmean, yend = overall), alpha = .3) +# Color adjustments made here...geom_point(aes(# color = abs(overall_to_prediction),size =abs(overall_to_prediction) ),color ="#33BBEE" ) +# Size mapped to abs(residuals)geom_point(aes(y = observed)) +# scale_color_continuous(low = "black", high = "red") + # Colors to use hereguides(color ="none", size ="none") +# Color legend removedgeom_point(aes(y = overall), shape =1, alpha = .3) + ggthemes::theme_tufte() +xlab("Average company experience") +ylab("Average salary per month") +geom_line(aes(x = exp_groupmean, y = overall, group =1), alpha =1) +ggtitle("Level-2-Residuen des Intercepts (Intercept-only Modell)")# use ggplotly only if html:if (knitr::is_html_output()) { intercept_only_plot |> plotly::ggplotly(tooltip ="company")} else { intercept_only_plot +geom_text(aes(label = company), # add text to plotnudge_x = .3 ) +lims(x =c(4, 7)) # zoom out a little, so everything can be seen}
\(~\)
In dieser Grafik ist der Firmenmittelwert der Erfahrung auf der X-Achse abgebildet, obwohl diese Variable nicht im Modell ist. Dadurch lassen sich die Firmen und deren Residuen bezüglich der Löhne zwischen diesem und der nächsten Grafik direkt vergleichen, weil sich die Datenpunkte in der Darstellung nicht verschieben. Wir erkennen an der horizontalen Gerade der Modellprädiktion entlang der X-Achse, dass der Einfluss der durchschnittlichen Erfahrung nicht mit-modelliert wurde.
Code
context.model <-lmer(salary ~ exp_centered + exp_groupmean + (1| company), data = df, REML =TRUE)companies <- df |>select(company) |>pull() |>levels()plot_df_context <-tibble(company = companies,exp_groupmean = df |>group_by(company) |>pull(exp_groupmean) |>unique(),overall_nogroupmean =fixef(context.model)["(Intercept)"] +mean(exp_groupmean) *fixef(context.model)["exp_groupmean"],overall =fixef(context.model)["(Intercept)"] + exp_groupmean *fixef(context.model)["exp_groupmean"],prediction = overall +ranef(context.model)$company |>select("(Intercept)") |>pull(),overall_to_prediction =ranef(context.model)$company |>select("(Intercept)") |>pull(),observed = df |>group_by(company) |>summarise(observed =mean(salary)) |>pull(observed))context_plot <-ggplot(aes(x = exp_groupmean, y = prediction, label = company),data = plot_df_context) +geom_segment(aes(xend = exp_groupmean, yend = overall), alpha = .3) +# Color adjustments made here...geom_point(aes(# color = abs(overall_to_prediction),size =abs(overall_to_prediction) ),color ="#33BBEE" ) +# Size mapped to abs(residuals)geom_point(aes(y = observed)) +# scale_color_continuous(low = "black", high = "red") + # Colors to use hereguides(color =FALSE, size =FALSE) +# Color legend removedgeom_line(aes(y = overall), alpha = .3) + ggthemes::theme_tufte() +xlab("Average company experience") +ylab("Average salary per month") +ggtitle("Level-2-Residuen des Intercepts (Kontexteffekt-Modell)")# use ggplotly only if html:if (knitr::is_html_output()) { context_plot |> plotly::ggplotly(tooltip ="company")} else { context_plot +geom_text(aes(label = company), # add text to plotnudge_x = .3 ) +lims(x =c(4, 7)) # zoom out a little, so everything can be seen}
2.1.2 Varianzerklärung durch Level-2-Prädiktor
Welcher Anteil der Level-2-Varianz des Intercepts wurde durch exp_groupmean erklärt?
Das Vergleichsmodell ist jetzt das Random-Intercept-Modell aus Kapitel 1, das nur den festen Effekt von exp_centered beinhaltet (und keinen Random Slope).
29.0 % der Lohnunterschiede zwischen den Firmen lassen sich durch Unterschiede in der durchschnittlichen Arbeitserfahrung der Mitarbeitenden einer Firma erklären.
2.1.3 Allgemeines Intercept-as-Outcome-Modell
Dies ist ein Modell mit Random Intercept, mit oder ohne Random Slope und mit Level-2-Haupteffekt (Prädiktion des Intercepts), aber ohne Prädiktor für den Slope (d.h. ohne Cross-Level-Interaktion).
Im Anwendungsbeispiel überprüfen wir, ob der Sektor (sector), in dem die Firmen tätig sind, einen Effekt auf salary hat, d.h. inwiefern die Höhe des Lohns davon abhängt, ob eine Firma im privaten oder öffentlichen Sektor operiert.
Der Effekt eines Level-2-Prädiktors könnte auch ohne weitere (Level-1-)Prädiktoren im Modell ermittelt werden. Man ist aber häufig gleichzeitig am Effekt eines Level-1-Prädiktors (hier: exp_centered) interessiert. Der Level-1-Prädiktor kann in diesem Modell entweder mit (\(\beta_{1i}=\gamma_{10} + \upsilon_{1i}\)) oder ohne Random-Slope (\(\beta_{1i}=\gamma_{10}\)) modelliert werden (der Unterschied bezüglich dieses Effekts ähnelt dem Unterschied zwischen dem Random-Coefficients-Modell und dem Random-Intercept-Modell, vgl. Kapitel 1 zu Modellen mit Level-1-Prädiktoren). Wir beschränken uns hier auf ein Intercept-as-Outcome-Modell mit Random-Slope.
Wie bei den anderen Modellen benutzen wir die lmer()-Funktion aus dem Package lme4:
Im Gegensatz zur Variable exp_groupmean (Level-2-Prädiktor im Kontexteffekt-Modell) ist sector eine kategoriale Variable (Faktor). Praktischerweise übernimmt lme4 die Dummy-Kodierung (mit der ersten Faktorstufe Private als Referenzkategorie) für uns.
# Fitten und abspeichern des Modellsintercept.as.outcome.model <-lmer( salary ~ exp_centered + sector + (exp_centered | company),data = df, REML =TRUE)# Durch das Modell vorhergesagte Werte abspeicherndf$intercept.as.outcome.preds <-predict(intercept.as.outcome.model)# Output anschauensummary(intercept.as.outcome.model)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: salary ~ exp_centered + sector + (exp_centered | company)
Data: df
REML criterion at convergence: 1857.5
Scaled residuals:
Min 1Q Median 3Q Max
-2.8806 -0.6584 -0.0054 0.5948 3.3679
Random effects:
Groups Name Variance Std.Dev. Corr
company (Intercept) 0.95886 0.9792
exp_centered 0.01844 0.1358 0.74
Residual 1.13659 1.0661
Number of obs: 600, groups: company, 20
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 8.66346 0.29156 19.53491 29.714 < 2e-16 ***
exp_centered 0.53072 0.04067 19.29436 13.049 5.03e-11 ***
sectorPublic 0.14829 0.37508 17.77711 0.395 0.697
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr) exp_cn
exp_centerd 0.406
sectorPublc -0.643 0.014
In der Stichprobe verdienen Angestellte im öffentlichen Sektor im Schnitt ca. 148 CHF mehr als Angestellte im privaten Sektor (\(\hat\gamma_{01} = 0.148\)), dieser Effekt ist aber nicht signifikant (\(p = 0.6973\)) und darf daher nicht weiter interpretiert werden. Auch die Interpretation des Intercepts \(\hat\gamma_{00} = 8.663\) hat sich verändert: Dieser bedeutet jetzt, dass der durchschnittliche Monatslohn für eine:n Angestellten einer (unbekannten) Firma im privaten Sektor (Referenzkategorie von sector) mit durchschnittlicher Erfahrung (= an der Stelle exp_centered = 0) ca. 8663 CHF beträgt.
2.2 Slope-as-Outcome-Modell (Modell 5)
In diesem Modell untersuchen wir, ob der firmenspezifische Effekt von exp_centered auch vom Sektor, in dem eine Firma operiert, abhängt. Wir sagen also den Effekt \(\beta_{1i}\) mit Hilfe des Level-2-Prädiktors sector vorher (“Slope-as-Outcome”). Bei einem signifikanten Cross-Level-Interaktionseffekt können wir schlussfolgern, dass sich die Effekte von exp_centered zwischen Firmen aus dem privaten Sektor und Firmen aus dem öffentlichen Sektor (im Schnitt über die Firmen des jeweiligen Sektors) unterscheiden.
Das bedeutet dann auch, dass die in Modell 3 (Random-Coefficents-Modell mit nur Level-1-Prädiktor exp_centered) ermittelte signifikante Level-2-Varianz des Slopes von exp_centered (\(\hat\sigma_{\upsilon_1}^2\)) signifikant reduziert wurde, indem ein Teil dieser Slope-Varianz jetzt durch die Sektorzugehörigkeit erklärt wird.
Auch in Modell 4 haben wir eine ähnlich hohe Slope-Varianz erhalten, diese aber nicht auf Signifikanz getestet. Streng genommen ist Modell 4 jetzt das Vergleichsmodell (und nicht Modell 3), da dieses wie Modell 5 den Level-2-Effekt von sector auf den Intercept enthält. Dieser kleine Unterschied spielt aber hauptsächlich für die Berechnung der erklärten Varianz des Slopes eine Rolle (s.u.).
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: salary ~ exp_centered * sector + (exp_centered | company)
Data: df
REML criterion at convergence: 1852.8
Scaled residuals:
Min 1Q Median 3Q Max
-2.8198 -0.6801 -0.0471 0.6089 3.3936
Random effects:
Groups Name Variance Std.Dev. Corr
company (Intercept) 0.865192 0.93016
exp_centered 0.008178 0.09043 0.83
Residual 1.136988 1.06630
Number of obs: 600, groups: company, 20
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 8.97788 0.30051 18.00223 29.875 < 2e-16 ***
exp_centered 0.64011 0.04838 19.43089 13.231 3.58e-11 ***
sectorPublic -0.48056 0.42499 18.00223 -1.131 0.27300
exp_centered:sectorPublic -0.21175 0.06736 18.29288 -3.143 0.00554 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr) exp_cn sctrPb
exp_centerd 0.482
sectorPublc -0.707 -0.341
exp_cntrd:P -0.346 -0.718 0.490
Das Ergebnis zeigt eine signifikante Cross-Level-Interaktion (\(\hat\gamma_{11} = -0.212, p = 0.0055\)) in die erwartete Richtung (niedrigere Lohnsteigerungen im Sektor Public). Der simple slope von exp_centered zeigt ausserdem die durchschnittliche Lohnsteigerung im privaten Sektor an (\(\hat\gamma_{10} = 0.64, p = 0)\). Die durchschnittliche Lohnsteigerung im öffentlichen Sektor können wir als \(\hat\gamma_{10} + \hat\gamma_{11} = 0.64 + (-0.212) = 0.428\) berechnen.
Im Output ausserdem ablesbar (gewissermassen als “Nebeneffekt”) ist das Ergebnis, dass durchschnittlich erfahrene Angestellte (exp_centered = 0) im öffentlichen Sektor nicht-signifikant weniger (\(\hat\gamma_{01} = -0.481, p = 0.273\)) verdienen als im privaten Sektor (bedingter Effekt/simple slope von sector im Term sectorPublic).
2.2.2 Modellvergleich (Signifikanztest) für die verbliebene Slope-Varianz
Jetzt möchten wir noch testen, ob die in Modell 5 verbliebene Slope-Varianz noch signifikant von 0 verschieden ist. Das machen wir über einen Modellvergleich mit einem Modell, das sich nur darin von unserem Slope-as-Outcome-Modell unterscheidet, dass es keine Slope-Varianz schätzt:
Auch das Ergebnis dieses Likelihod-Ratio-Tests \((LRT=7.1649)\) müssen wir mit dem kritischen Wert 5.14 vergleichen oder einen korrigierten p-Wert berechnen:
Die Varianz von exp_centered ist also immer noch signifikant. Es verbleiben daher nach Berücksichtigung von sector als Moderatorvariable noch Unterschiede im Effekt von exp_centered zwischen den Firmen innerhalb der beiden Sektoren.
2.2.3 Varianzerklärung durch Cross-Level-Interaktionseffekt
Durch den signifikanten Cross-Level-Interaktionseffekt wissen wir bereits, dass die in den Modellen 3 bzw. 4 vorhandenen exp_centered-Steigungsunterschiede zwischen den Firmen auch auf den Sektor, in dem die Firmen operieren, zurückzuführen sind (obwohl danach noch signifikante Slope-Varianz verbleibt).
Welcher Anteil der Level-2-Varianz des exp_centered-Slopes wurde also durch sector erklärt (siehe Eid et al., 2017, S. 753)? Dazu vergleichen wir mit dem Intercept-as-Outcome-Modell von oben, welches sich nur durch den Interaktionseffekt von Modell 5 unterscheidet.
Im Sinne einer Effektgrösse für die Cross-Level-Interaktion (\(\hat\gamma_{11}\)) wurden 55.66 % der Slope-Varianz von exp_centered durch Sektorenunterschiede im Effekt von exp_centered auf salary erklärt.
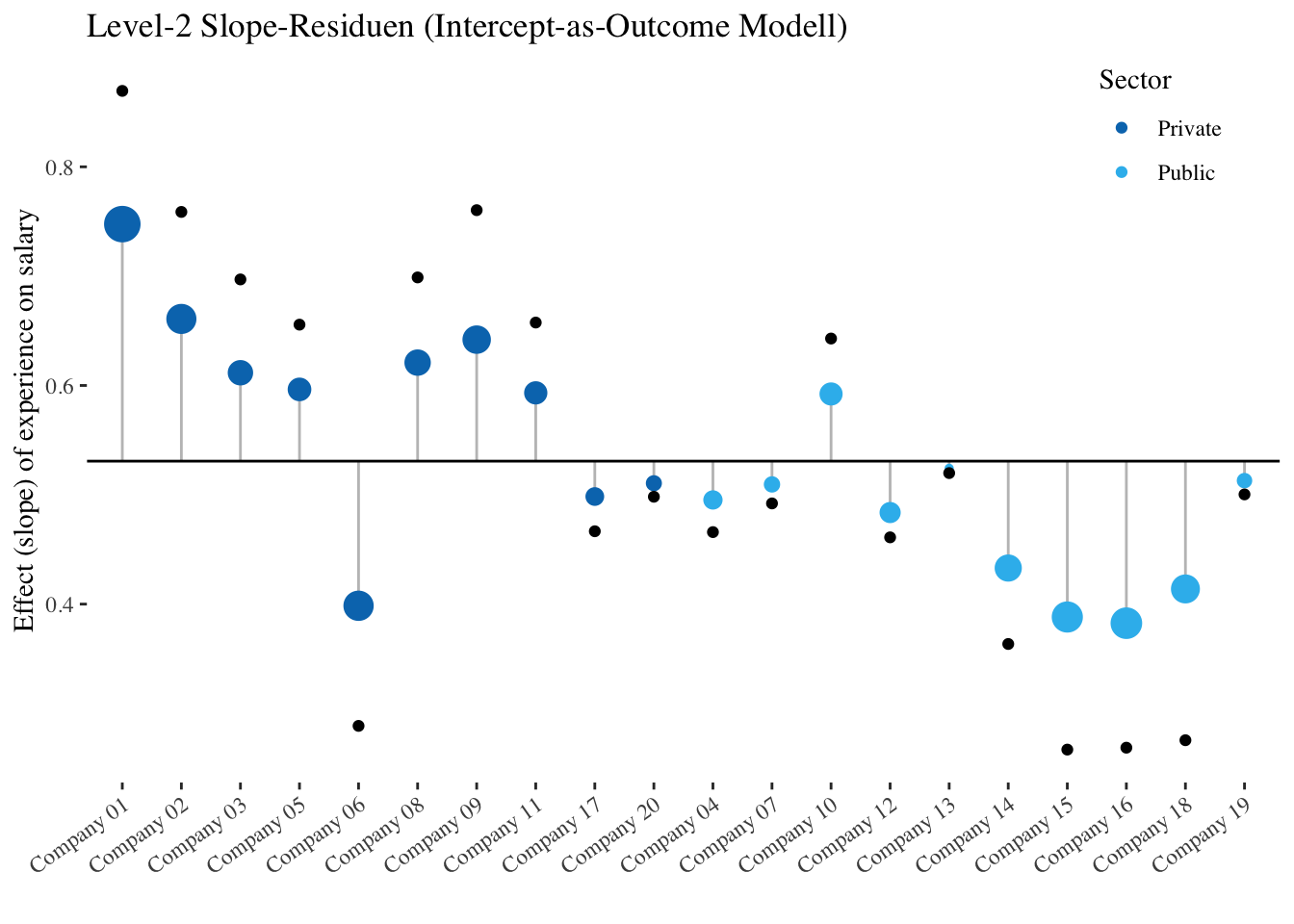
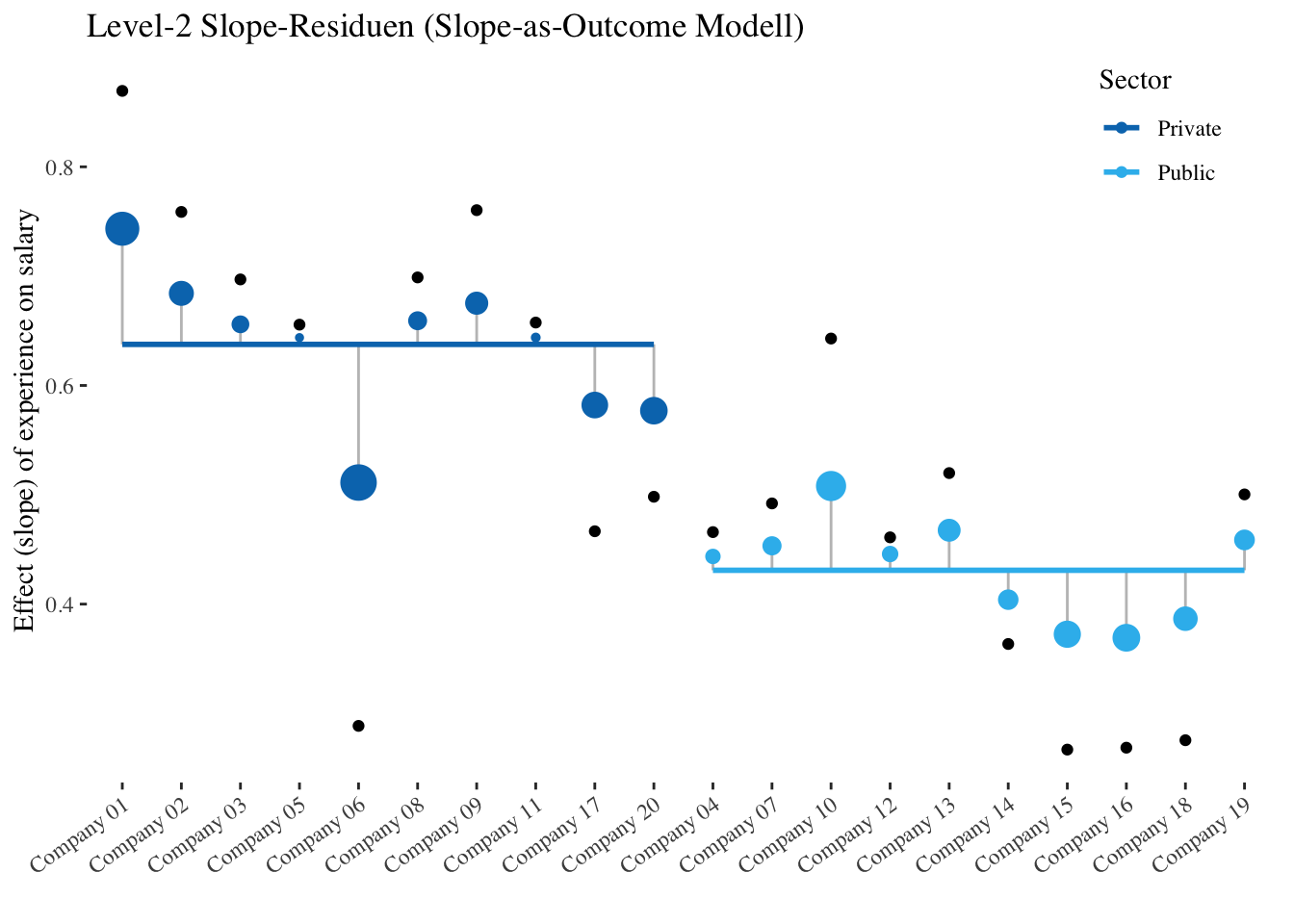
In den folgenden beiden Plots wird die Auswirkung der Cross-Level-Interaktion auf die Slope-Residuen von exp_centered veranschaulicht. Der erste Plot zeigt die Slope-Residuen relativ zum durchschnittlichen Effekt von exp_centered im Intercept-as-Outcome Modell (\(\hat\gamma_{10} = 0.531\)). Der zweite Plot zeigt die Slope-Residuen im Modell mit Cross-Level-Interaktion (Slope-as-Outcome-Modell) relativ zu den jeweiligen Simple Slopes von experience in den Sektoren Private und Public. Die kleinen schwarzen Punkte stehen wieder für die pro Gruppe in getrennten Regressionen (d.h. ohne Shrinkage) geschätzten Slopes. Klar erkennbar ist, dass die Residuen über alle Firmen hinweg im Slope-as-Outcome Modell deutlich kleiner ausfallen.
Code
intercept.as.outcome <-lmer(salary ~ exp_centered + sector + (-1+ exp_centered | company) + (1| company), data = df, REML =TRUE)slope.as.outcome.lm <- lme4::lmList(formula = salary ~ exp_centered | company, data = df)plot_df_iao_s <-tibble(company = companies,sector = df |>group_by(company) |>summarise(sector =unique(sector)) |>pull(),overall_nosector =fixef(intercept.as.outcome)["exp_centered"],prediction = overall_nosector + {ranef(intercept.as.outcome)$company |>select("exp_centered") |>pull() },overall_to_prediction = {ranef(intercept.as.outcome)$company |>select("exp_centered") |>pull() },observed =coef(slope.as.outcome.lm) |>select("exp_centered") |>pull()) |>arrange(sector)plot_df_iao_s <- plot_df_iao_s |>mutate(company =factor(company, c(unique(company))))ggplot(aes(x = company, y = prediction),data = plot_df_iao_s) +geom_segment(aes(xend = company, yend = overall_nosector), alpha = .3) +# Color adjustments made here...geom_point(aes(size =abs(overall_to_prediction), color = sector)) +# size mapped to abs(residuals)geom_point(aes(y = observed)) +# scale_color_continuous(low = "black", high = "red") + # Colors to use hereguides(size ="none") +# Color legend removedlabs(color ="Sector") +# Change title of color legendgeom_hline(aes(yintercept = plot_df_iao_s$overall_nosector[[1]])) + ggthemes::theme_tufte() +scale_color_manual(values =c("#0077BB", "#33BBEE")) +xlab("") +ylab("Effect (slope) of experience on salary") +ggtitle("Level-2 Slope-Residuen (Intercept-as-Outcome Modell)") +# geom_text(aes(label = company), hjust = 1, vjust = 0) +# still have to fix ittheme(axis.text.x =element_text(angle =35, hjust =1),legend.position ="inside",legend.position.inside =c(.9, .9) )
Code
slope.as.outcome <-lmer(salary ~ exp_centered * sector + (exp_centered -1| company) + (1| company), data = df, REML =TRUE)# to get the "observed" slopes without shrinkage we have to fit a linear model for each company:slope.as.outcome.lm <- lme4::lmList(formula = salary ~ exp_centered | company, data = df)plot_df_sao <-tibble(company = companies,sector = df |>group_by(company) |>summarise(sector =unique(sector)) |>pull(),overall_nosector =fixef(slope.as.outcome)["exp_centered"] +mean(dummy(sector)) *fixef(slope.as.outcome)["exp_centered:sectorPublic"],overall =fixef(slope.as.outcome)["exp_centered"] +dummy(sector)[, 1] *fixef(slope.as.outcome)[["exp_centered:sectorPublic"]],prediction = overall + {ranef(slope.as.outcome)$company |>select("exp_centered") |>pull() },overall_to_prediction = {ranef(slope.as.outcome)$company |>select("exp_centered") |>pull() },overall_nosector_to_prediction = prediction - overall_nosector,observed =coef(slope.as.outcome.lm) |>select("exp_centered") |>pull()) |>arrange(sector)# reorder companiesplot_df_sao <- plot_df_sao |>mutate(company =factor(company, c(unique(company))))ggplot(aes(x = company, y = prediction),data = plot_df_sao) +geom_segment(aes(xend = company, yend = overall), alpha = .3) +geom_point(aes(color = sector, size =abs(overall_to_prediction))) +# Color mapped to abs(residuals)geom_point(aes(y = observed)) +scale_color_manual(values =c("#0077BB", "#33BBEE")) +guides(size =FALSE) +# Color legend removedlabs(color ="Sector") +# Change title of color legendgeom_smooth(aes(x = company, y = overall, color = sector, group = sector), method ="lm", se =FALSE, alpha =1) + ggthemes::theme_tufte() +xlab("") +ylab("Effect (slope) of exp_centered on salary") +ggtitle("Level-2 Slope-Residuen (Slope-as-Outcome Modell)") +theme(axis.text.x =element_text(angle =35, hjust =1),legend.position ="inside",legend.position.inside =c(.9, .9) )
2.3 Literatur
Eid, M., Gollwitzer, M., & Schmitt, M. (2017). Statistik und Forschungsmethoden: mit Online-Materialien (5., korrigierte Auflage). Beltz.