3 Importing Datasets
A first step in data analysis is importing datasets. These can be in several formats. Fortunately, R has several packages that allow us to easily import data from comma-separated value (CSV), SPSS and Excel files.
You will find the following datasets on ILIAS:
- zufriedenheit.csv
- zufriedenheit-semicolon.csv
- zufriedenheit.sav
- zufriedenheit.xls
This is a generated dataset. The variables are a satisfaction rating, recorded at two time points for four subjects.
zufriedenheit.csv is a text file, in which the columns are separated by commas (hence the name). zufriedenheit-semicolon.csv is also a text file, but with a semi-colon as the delimiter. zufriedenheit.sav and zufriedenheit.xls are SPSS and Excel files.
In your RStudio project folder in the file system of your computer, create a new directory named ‘data’ and save the files you downloaded.
In RStudio, there are two ways of importing files:
Using functions:
read_csv(),read_csv2()(for ‘;’ delimiters),read_sav()andread_excel().Via the GUI: You can access this functionality either through ‘File > Import Dataset’ or in the Environment pane.
The second option is easier to use, and has the advantage that R will generate all code for importing datasets for us, which can be copied for subsequent use.
3.1 Comma-separated value (CSV) files
The functions we need for importimg CSV files are available in the readr package. This needs to be loaded:
library(readr)Alternatively, we can just load all tidyverse packages:
library(tidyverse)We will first import the data files using the GUI. In Environment, click on Import Dataset > From Text (readr) (or ‘File > Import Dataset > From Text (readr)’). You will see a dialogue containing a Code Preview with the following code:
library(readr)
dataset <- read_csv(NULL)
View(dataset)On the left (bottom) you will find all options for importing the data. These options are all arguments of the read_csv() function (or the more general read_delim() funtion):
args(read_csv)
#> function (file, col_names = TRUE, col_types = NULL, locale = default_locale(),
#> na = c("", "NA"), quoted_na = TRUE, quote = "\"", comment = "",
#> trim_ws = TRUE, skip = 0, n_max = Inf, guess_max = min(1000,
#> n_max), progress = show_progress())
#> NULLIn the File Browser you can select the zufriedenheit.csv file. After doing so you will see Data Preview.
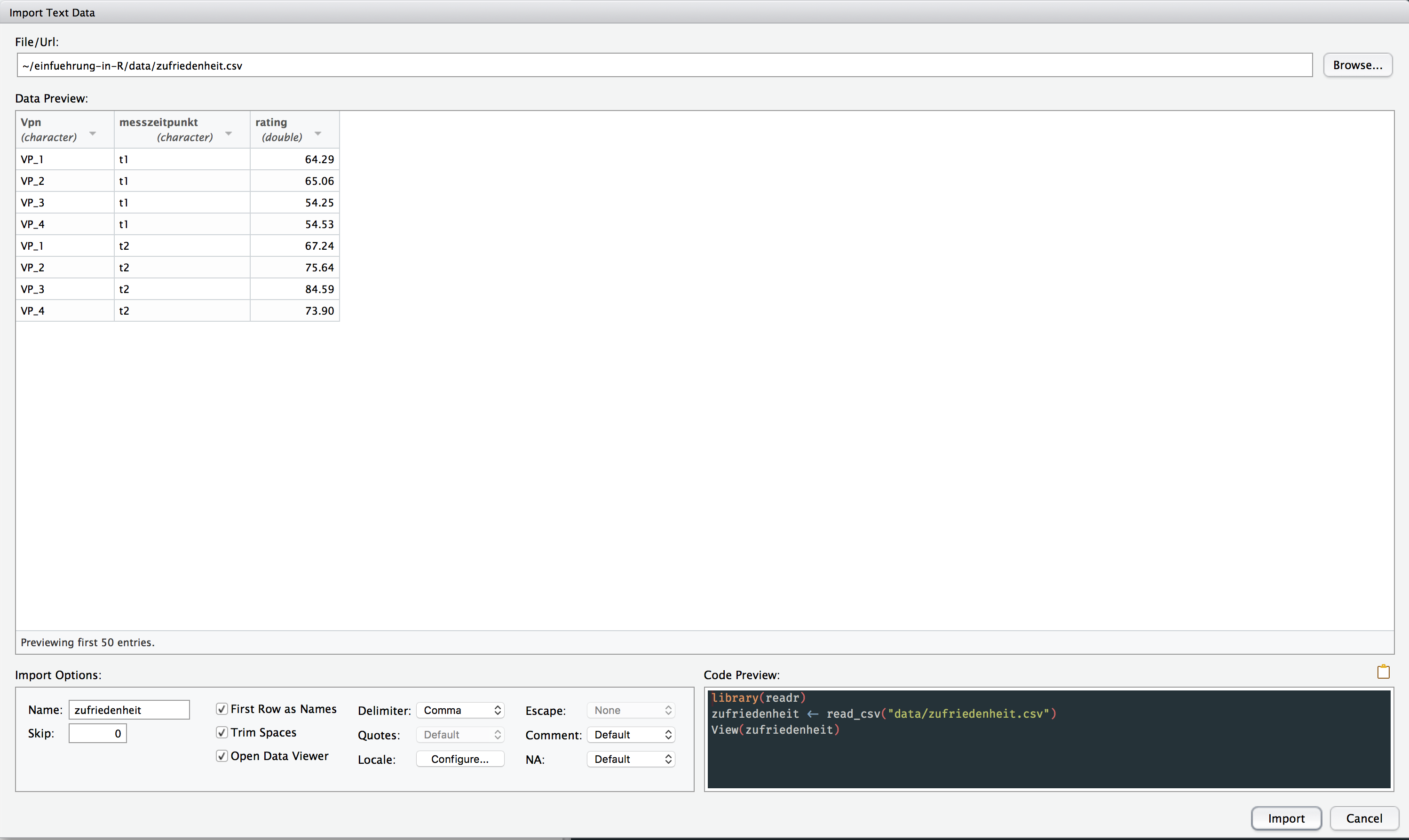
The variables Vpn and messzeitpunkt have been imported as character vectors. These will need to be converted to factors. Under Import Options a file name is generated automatically. This is simply the file name, minus the .csv suffix.
Try to discover what happens when you play around with the options, e.g. “First Row as Names”.
Now click on Import. A new data frame (tibble) with the name zufriedenheit will appear in the Environment pane, and the generated R code is printed to the console.
library(readr)
zufriedenheit <- read_csv("data/zufriedenheit.csv")
#> Parsed with column specification:
#> cols(
#> Vpn = col_character(),
#> messzeitpunkt = col_character(),
#> rating = col_double()
#> )We still have to convert the grouping variables to factors:
zufriedenheit$Vpn <- as.factor(zufriedenheit$Vpn)
zufriedenheit$messzeitpunkt <- as.factor(zufriedenheit$messzeitpunkt)zufriedenheit
#> # A tibble: 8 x 3
#> Vpn messzeitpunkt rating
#> <fct> <fct> <dbl>
#> 1 VP_1 t1 64.3
#> 2 VP_2 t1 65.1
#> 3 VP_3 t1 54.2
#> 4 VP_4 t1 54.5
#> 5 VP_1 t2 67.2
#> 6 VP_2 t2 75.6
#> # ... with 2 more rows
Now do the same with the semi-colon delimited file zufriedenheit-semicolon.csv. This is something that you frequently be confronted with if your computer uses a German locale.
You should see the following code in the Code Preview:
library(readr)
zufriedenheit_semicolon <- read_delim("data/zufriedenheit-semicolon.csv",
";", escape_double = FALSE, trim_ws = TRUE)
Try importing both files using the R commnands. For the semi-colon file you can use the function read_csv2().
If you want to save a data frame as a CSV file, you can use the function write_csv():
write_csv(x = zufriedenheit_long, path = "data/zufriedenheit.csv")3.2 SPSS datasets
We can import the same dataset, but this time from the SPSS file format (zufriedenheit.sav). There is a package called haven; this provides the function read_sav(). We can load the package to make the function available:
library(haven)
zufriedenheit_spss <- read_sav("data/zufriedenheit.sav")But, as before, we can also use the GUI. In the Environment pane, click on Import Dataset > From SPSS, and choose the file. You will see a Code Preview:
In contrast to importing CSV files, we have no options when importing from SPSS except for the name of the data frame, which we will change to zufriedenheit_spss.
Now you can click on Import. In the Environment pane, the newly created varibale will appear. Variables imported from SPSS can have additional attributes, the most important of which is the labels attribute:
zufriedenheit_spss$Vpn
#>
#> [1] 1 2 3 4 1 2 3 4
#> attr(,"format.spss")
#> [1] "F8.0"
#> attr(,"labels")
#> VP_1 VP_2 VP_3 VP_4
#> 1 2 3 4This contains the SPSS value labels. Using this, we can look up what type of coding scheme was used for categorical variables. If the values 0 and 1 were used for the sex variable, we determine which sex has the value 0.
If we want to convert variables to factors, we can use the function as_factor() from the haven package. This allows us to use either the SPSS values or value labels as levels of the factor in R. This is achieved by using the argument levels; this can take the values "default", "labels", "values" or "both" (you can inspect help page using ?as_factor). "default" seems to be the most sensible option - this means that labels are used if available and otherwise the values themselves are used. The other options are "both" (values and value labels are combined), "label" (labels only) and "values" (values only).
Arguments of the as_factor() function
levels
How to create the levels of the generated factor:
"default": uses labels where available, otherwise the values. Labels are sorted by value.
"both": like "default", but pastes together the level and value
"label": use only the labels; unlabelled values become NA
"values: use only the values
ordered
If TRUE create an ordered (ordinal) factor, if FALSE (the default) create a regular (nominal) factor.The argument ordered allows us to create an ordered factor, if the ordering of the factor levels is important.
zufriedenheit_spss$Vpn <- as_factor(zufriedenheit_spss$Vpn,
levels = "default")
zufriedenheit_spss$messzeitpunkt <- as_factor(zufriedenheit_spss$messzeitpunkt,
levels = "default")We can also save a data frame in the SPSS file format using the write_save() function:
write_sav(data = zufriedenheit_long, path = "data/zufriedenheit.sav")
Download and import the file called Beispieldatensatz.sav from ILIAS. Which value labels do the categorical variables have?
3.3 Excel files
We can also import Excel spreadsheets. Click on Import Dataset > From Excel, and then choose the file you want to import. We will call the data frame zufriedenheit_xls. Underneath the Name text box there is a drop-down menu entitled Sheet. This allows you to specify which worksheet you want to import. You should get the following R code in the Code Preview:
library(readxl)
zufriedenheit_xls <- read_excel("data/zufriedenheit.xlsx",
sheet = "zufriedenheit")The function we are using is called read_excel() and is available in the readxl package (not part of the tidyverse).
Categorical variables should again be converted to factors:
zufriedenheit_xls$Vpn <- as.factor(zufriedenheit_xls$Vpn)
zufriedenheit_xls$messzeitpunkt <- as.factor(zufriedenheit_xls$messzeitpunkt)3.4 RData files
The last option is an RData file. This is a binary file format and has the advantage that we can combine multiple R objects, including all their attributes, in a single file. This is very useful; when exporting to a text file, such as CSV, all metadata will be lost. A further advantage is that the file may be compressed in order to save space. However, this file is specific to R, and thus may not be the best option when sharing your data with other people.
You can save objects in your workspace as .RData (or .Rda) files with the function save():
save(zufriedenheit, file = "data/zufriedenheit.Rda")You can also save several objects in one go:
save(zufriedenheit, zufriedenheit_spss, zufriedenheit_xls,
file = "data/zufriedenheit_alle.Rda")The file can be loaded using the function load():
load(file = "data/zufriedenheit_alle.Rda")3.5 Exercises
Importing datasets 1
Download and import the file
Therapy.savfrom ILIAS, using both the GUI and the functionread_sav().Check the coding of the grouping variables. Which level should the reference category?
Convert to grouping variables to factors.
Importing datasets 2
Generate a (simulated) dataset and export it either as a
CSV,xlsodersavfile. This dataset should contain at least a numeric and a grouping variable. Exchange files with a partner.You will receive a file from your partner. Try to import this, and perform all necessary conversions.